In this post, we give a short tutorial on consistency levels --- explaining what they do, and how they work. Much of the existing literature and online discussion of consistency levels are done in the context of multi-processor or distributed systems that operate on a single data item at a time, without the concept of a “transaction”. In this post we give some direction for how to think about consistency levels in the context of ACID-compliant database systems.
What is a consistency level?
One point of confusion that we can eliminate at this point is that the phrase “consistency level” is not typically used in the context of ACID consistency. This is because the C of ACID is almost entirely the responsibility of the application developer --- only the developer can ensure that the code they place inside a transaction does not violate application semantics when it is run in isolation. ACID is really a misnomer --- really it should be AID, since only those three (atomicity, isolation, and durability) are in the realm of system guarantees. [Joe Hellerstein claims that he was taught that the C in ACID was only included to make an LSD pun, but acknowledges that this may be apocryphal.]
When we talk about consistency levels, we’re really referring the the C of CAP. In this context, perfect consistency --- usually referred to as “strict consistency” --- would imply that the system ensures that all reads reflect all previous writes --- no matter where those writes were performed. Any consistency level below “perfect” consistency enables situations to occur where a read does not return the most recent write of a data item. [Side note: the C of CAP in the original CAP paper refers to something called “atomic consistency” which is slightly weaker than strict consistency but still considered “perfect” for practical purposes. We’ll discuss the difference later in this post.]
Depending on how a particular system is architected, perfect consistency becomes easier or harder to achieve. In poorly designed systems, achieving perfection comes with a prohibitive performance and availability cost, and users of such systems are pushed to accept guarantees significantly short of perfection. However, even in well designed systems, there is often a non-trivial performance benefit achieved by accepting guarantees short of perfection.
An overview of well-known consistency levels

In sequential consistency, all writes --- no matter which thread made the write, and no matter which data item was written to --- are globally ordered. Every single thread of execution must see the writes occurring in this order. For example, if one thread saw data X being updated to 5, and then later saw Y being updated to 10, every single thread must see the update of X happening before the update of Y. If any thread sees the new value of Y but the old value of X, sequential consistency would be violated. This example is shown in Figure 1. In this figure, time gets later as you move to the right in the figure, and there are 4 threads of execution: P1, P2, P3, and P4. Every thread (that reads X and Y) sees the update of X from 0 to 5 happening before the update of Y from 0 to 10. Threads: P1 and P2 write X and Y respectively, but do not read either one. Thread P3 sees the new value of X and subsequently sees the old value of Y. This is only possible if the update to X happened before the update to Y. Thread P4 only sees the new values of X and Y, so it does not see which one happened first. Thus, all threads agree that it is possible that the update of X happened before the update to Y. Contrast this to Figure 2, below, in which P3 and P4 see clearly different orders of the updates to X and Y --- P3 sees the new value of X (5) and subsequently the old value of Y (0), while P4 sees the new value of Y (10) and subsequently the old value of X (0). Figure 2 is thus not a sequentially consistent schedule.

In general, sequential consistency does not place any requirements on how to order the writes. In our example, the write to X happened in real time before the write to Y. Nonetheless, as long as every thread agrees to see the write to Y as happening before the write to X, sequential consistency allows the official history to be different that what occurred according to real time (the only restriction is that writes and reads originating from the same thread of execution cannot be reordered). See Figure 3 for an example of this.

In contrast to sequential consistency, strict consistency does place real time requirements on how to order the writes. It assumes that it is always possible to know what time it currently is with zero error --- i.e. that every thread of execution agree on the precise current time. The order of the writes in the sequential order must be equal to the real time that these writes were issued. Furthermore, every read operation must read the value of the most recent write in real time --- no matter which thread of execution initiated that write. In a distributed system (and even multi-processor single-server systems), it is impossible in practice to have global agreement on precise current time, which renders strict consistency to be mostly of theoretical interest.
None of Figures 1, 2, or 3 above satisfy strict consistency because they all contain either a read of x=0 or a read of y=0 after the value of x or y has been written to a new value. However, Figure 4 below satisfies strict consistency since all reads reflect the most recent write in real time:

In a distributed/replicated system, where writes and reads can originate anywhere, the highest level of consistency obtained in practice is linearizability (also known as “atomic consistency” which is what it is called in the CAP theorem). Linearizability is very similar to strict consistency: both are extensions of sequential consistency that impose real time constraints on writes. The difference is that the linearizability model acknowledges that there is a period of time that occurs between when an operation is submitted to the system, and when the system responds with an acknowledgement that it was completed. In a distributed system, the sending of the write request to the correct location(s) --- which may include replication --- can occur during this time period. A linearizability guarantee does not place any ordering constraints on operations that occur with overlapping start and end times. The only ordering constraint is for operations that do not overlap in time --- only in those cases does the earlier write have to be seen before the later write.

Figure 5 above shows an example of a schedule that is linearizable, but not strictly consistent. It is not strictly consistency since the read of X by P3 is initiated (and returns) slightly after the write of X by P1, but still sees the old value. Nonetheless, it is linearizable because this read of X by P3 and write of X by P1 overlap in time, and therefore linearizability does not require the read of X by P3 to see the result of the write of X by P1.
While linearizability and strict consistency are stronger than sequential consistency, sequential consistency is by itself a very high level of consistency, and there exist many consistency levels below it.
Causal consistency is a popular and useful consistency level that is slightly below sequential consistency. In sequential consistency, all writes must be globally ordered --- even if they are totally unrelated to each other. Causal consistency does not enforce orderings of unrelated writes. However, if a thread of execution performs a read of some data item (call it X) and then writes that data item or a different one (call it Y), it assumes that the subsequent write may have been caused by the read. Therefore, it enforces the order of X and Y --- specifically all threads of execution must observe the write of Y after the write of X.

As an example, compare Figure 6 (above) with Figure 2. In Figure 2, P3 saw the write to X happening before the write to Y, but P4 saw the write to Y happening before the write to X. This violates sequential consistency, but not causal consistency. However, in Figure 6, P2 read the write to X before performing the write to Y. That places a causal constraint between the write to X and Y --- Y must happen after X. Therefore, when P4 sees the write to Y without the write to X, causal consistency is violated.
Eventual consistency is even weaker --- even causally dependent writes may become visible out of order. For example, despite violating every other consistency guarantee that we have discussed so far, Figure 6 does not necessarily violate eventual consistency. The only guarantee in eventual consistency is that if there are no writes for a “long” period of time (where the definition of “long” is system dependent), every thread of execution will agree on the value of the last write. So as long as P4 eventually sees the new value of X (5) at some later point in time (not shown in Figure 6), then eventual consistency is maintained.
Strong consistency vs. Weak consistency
Strict consistency and linearizability/atomic consistency are typically thought of as “strong” consistency levels. In many cases, sequential consistency is also referred to as a strong consistency level. The key feature that each of these consistency levels share is that the state of the database goes through a universally agreed-upon sequence of state changes. This allows the realities of replication to be hidden to the end user. In essence, the view of the database to the user is that there is only one copy of the database that continuously makes state transitions in a forward direction. In contrast, weaker consistency levels (such as causal consistency and eventual consistency) allow different views of the database state to see different progression of steps in database state ---- a clear impossibility unless there is more than one copy of the database. Thus, for weaker levels of consistency, the application developer must be explicitly aware of the replicated nature of the data in the database, thereby increasing the complexity of development relative to strong consistency.
Transactions and consistency levels
As we discussed above, consistency levels have historically been defined in terms of individual reads or writes of a data item. This makes the discussion of consistency levels hard to apply to the context of database systems in which groups of read and write operations occur together in atomic transactions. Indeed, both the research literature and vendor documentation (for those vendors that offer multiple consistency levels) are extremely confusing and do not take a uniform approach when it comes to applying consistency levels in the context of database systems.
I think that the simplest way to reason about consistency levels in the presence of database transactions is to make only minor adjustments to the consistency models we discussed earlier. We still view consistency as threads of execution sending read and write requests to a shared data store. The only difference is that we annotate each read and write request with the transaction identifier of the transaction that initiated each request. If each thread of execution can only process one transaction at a time, and transactions can not be processed by more than one thread of execution, then the traditional timeline consistency diagrams need only be supplemented with rectangular boundaries indicating the start and end point of each transaction within a thread of execution, as shown in the figure below.
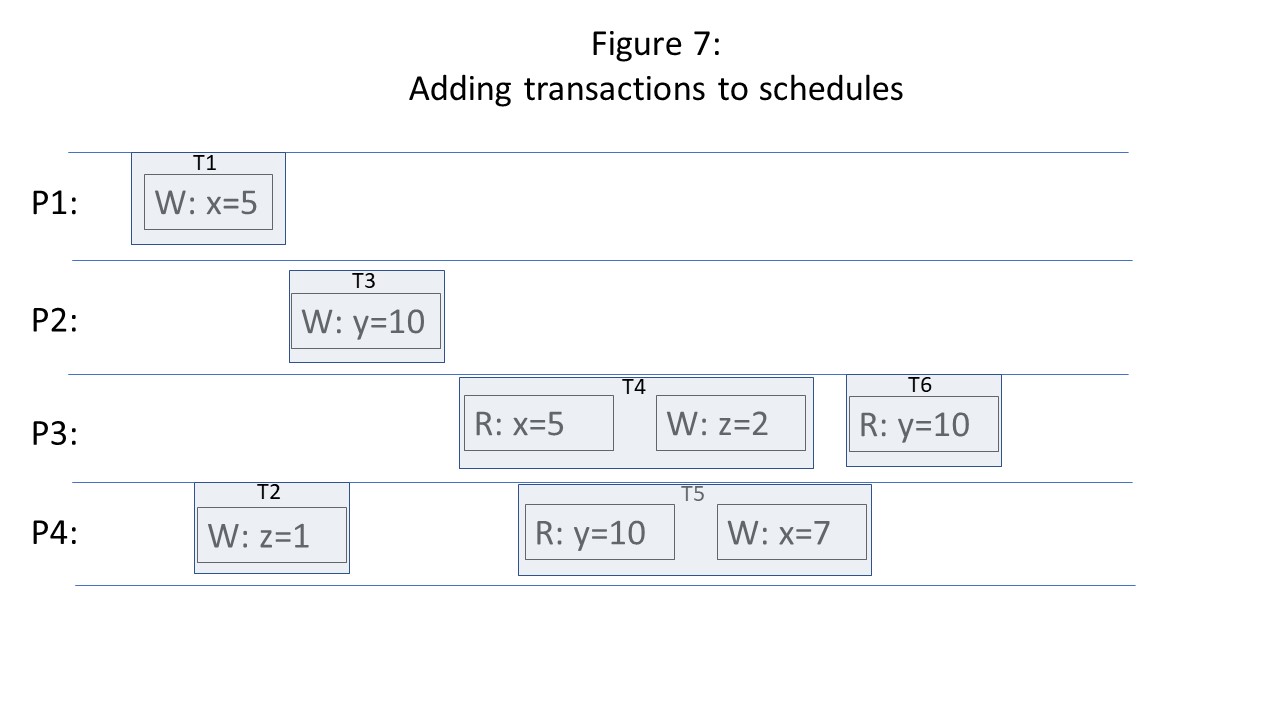
The presence of a transaction in a consistency diagram adds additional constraints corresponding to AID of ACID: all of the reads and writes within the transaction succeed or fail together (atomicity), they are isolated from other concurrently running transactions (the degree of isolation will depend on the isolation level), and writes of committed transactions will outlive all kinds of system failure (durability).
The atomicity and durability guarantees of transactions are pretty easy to cognitively separate from consistency guarantees, because they deal with fundamentally different concepts. The problem is isolation. Consistency guarantees specify how and when writes are visible to threads of execution that read database state. Isolation guarantees also place limitations on when writes become visible. This conceptual overlap of isolation and consistency guarantees is the source of much confusion. In the next post of this series I plan to give a tutorial for understanding the difference between isolation levels and consistency levels.
"This is because the C of ACID is almost entirely the responsibility of the application developer --- only the developer can ensure that the code they place inside a transaction does not violate application semantics when it is run in isolation. ACID is really a misnomer --- really it should be AID, since only those three (atomicity, isolation, and durability) are in the realm of system guarantees"
ReplyDeleteDo you mean this as an observation regarding the state-of-the-art? Or actually as a desirable property of a DBMS?
I would agree that existing DBMSes have poor support for arbitrary integrity constraints (and therefore semantic consistency). But, I don't see that as desirable; in fact, quite the opposite. I consider it a failing of the industry that we still only have platforms that support simple constraints (e.g. unique keys), rather than complex constraints that we could express using the full power of predicate logic.
Assuming we had DBMSes that supported such complex constraints, and, assuming beforehand some developer had declared such constraints to the system _in their entirety_, doesn't that mean that such constraints --- and therefore consistency --- does (or should!) actually lie in the realm of system guarantees?
Hi Joe,
DeleteI agree with pretty much everything you say. As you mentioned, the user would have to declare such constraints in their entirety. At that point, enforcing those constraints would lie in the realm of system guarantees. But the reliance on the user to declare these constraints still puts the C of ACID as a different type of guarantee than the AID.