Apache Parquet and Apache ORC have become a popular file formats for storing data in the Hadoop ecosystem. Their primary value proposition revolves around their “columnar data representation format”. To quickly explain what this means: many people model their data in a set of two dimensional tables where each row corresponds to an entity, and each column an attribute about that entity. However, storage is one-dimensional --- you can only read data sequentially from memory or disk in one dimension. Therefore, there are two primary options for storing tables on storage: Store one row sequentially, followed by the next row, and then the next one, etc; or store the first column sequentially, followed by the next column, and then the next one, etc.
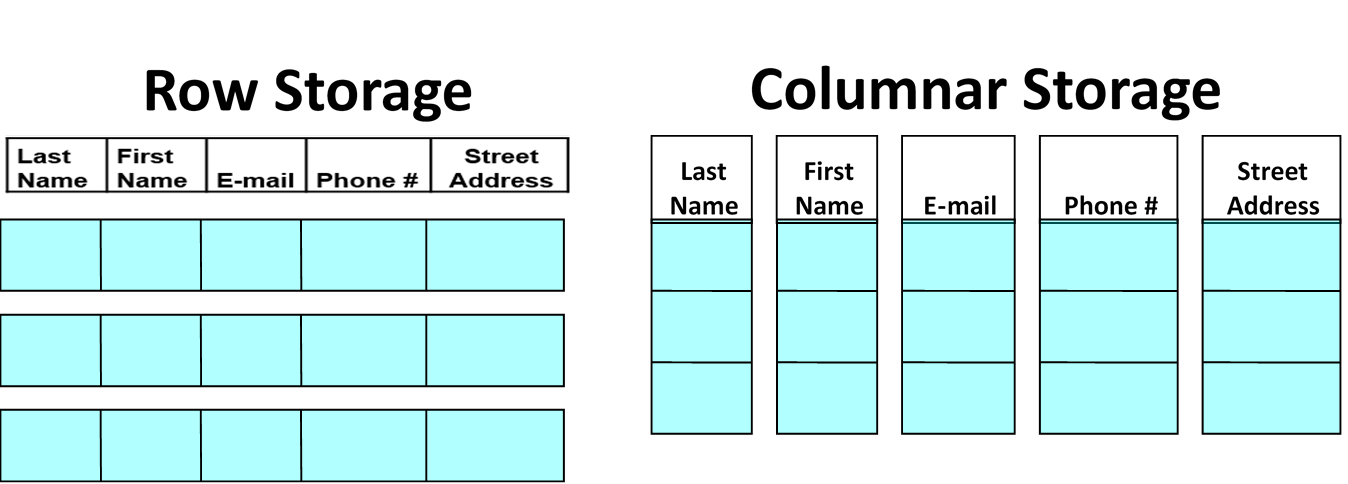 |
| Storage layout difference between row- and column-oriented formats |
For decades, the vast majority of data engines used row-oriented storage formats. This is because many early data application workloads revolved around reading, writing, and updating single entities at a time. If you store data using a columnar format and you want to extract all attributes for a particular entity, the system must jump around, finding the data for that entity from each of the separately-stored attributes. This results in a random access pattern, which results in slower access times than sequential access patterns. Therefore, columnar storage formats are a poor fit for workloads that tend to read and write entire entities at once, such as OLTP (transactional) workloads. Over time, workloads became more complex, and data analytics workloads emerged that tended to focus on only a few attributes at once; scanning through large quantities of entities to aggregate and/or process values of these attributes. Thus, storing data in a columnar fashion became more viable, and columnar formats resulted in sequential, high performance access patterns for these workloads.
Apache Arrow has recently been released with seemingly an identical value proposition as Apache Parquet and Apache ORC: it is a columnar data representation format that accelerates data analytics workloads. Yes, it is true that Parquet and ORC are designed to be used for storage on disk and Arrow is designed to be used for storage in memory. But disk and memory share the fundamental similarity that sequential access is faster than random access, and therefore the analytics workloads which tend to scan through attributes of data will perform more optimally if data is stored in columnar format no matter where data is stored --- in memory or on disk. And if that’s the case, the workloads for which Parquet and ORC are a good fit will be the identical set of workloads for which Arrow is a good fit. If so, why do we need two different Apache projects?
Before we answer this question, let us run a simple experiment to validate the claimed advantages of column-stores. On an Amazon EC2 t2.medium instance, I created a table with 60,000,000 rows (entities) in main memory. Each row contained six attributes (columns), all of them 32-bit integers. Each row is therefore 24 bytes, and the entire table is almost 1.5GB. I created both row-oriented and column-oriented versions of this table, where the row-oriented version stores the first 24-byte row, followed by the next one, etc; and the column-oriented version stores the entire first column, followed by the next one, etc. I then ran a simple query ideally suited for column-stores --- I simply search the entire first column for a particular value. The column-oriented version of my table should therefore have to scan though just the first column and will never need to access the other five columns. Therefore it will need to scan through 60,000,000 values * 4 bytes per value = almost 0.25GB. Meanwhile the row-store will need to scan through the entire 1.5GB table because the granularity with which data can be passed from memory to the CPU (a cache line) is larger than the 24-byte tuple. Therefore, it is impossible to read just the relevant first attribute from memory without reading the other five attributes as well. So if the column-store has to read 0.25GB of data and the row-store has to read 1.5GB of data, you might expect the column-store to be 6 times faster than the row-store. However, the actual results are presented in the table below:
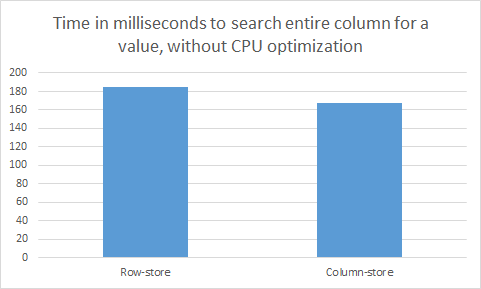
Surprisingly, the row-store and the column-store perform almost identically, despite the query being ideally suited for a column-store. The reason why this is the case is that I turned off all CPU optimizations (such as vectorization / SIMD processing) for this query. This resulted in the query being bottlenecked by CPU processing, despite the tiny amount of CPU work that has to happen for this query (just a simple integer comparison operation per row). To understand how it is possible for such a simple query to be bottlenecked by the CPU, we need to understand some basic performance specifications of typical machines. As a rough rule of thumb, sequential scans through memory can feed data from memory to the CPU at a rate of around 30GB a second. However, a modern CPU processor runs at approximately 3 GHz --- in other words they can process around 3 billion instructions a second. So even if the processor is doing a 4-byte integer comparison every single cycle, it is processing no more than 12GB a second --- a far smaller rate than the 30GB a second of data that can be sent to it. Therefore, CPU is the bottleneck, and it does not matter that the column-store only needs to send one sixth of the data from memory to the CPU relative to a row-store.
On the other hand, if I turn on CPU optimizations (by adding the ‘-O3’ compiler flag), the equation is very different. Most notably, the compiler can vectorize simple operations such as the comparison operation from our query. What this means is that originally each of the 60,000,000 integer comparisons that are required for this query happened sequentially --- each one occurring in a separate instruction from the previous. However, once vectorization is turned on, most processors can actually take four (or more) contiguous elements of our column, and do the comparison operation for all four of these elements in parallel --- in a single instruction. This effectively makes the CPU go 4 times faster (or more if it can do more than 4 elements in parallel). However, this vectorization optimization only works if each of the four elements fit in the processor register at once, which roughly means that they have to be contiguous in memory. Therefore, the column-store is able to take advantage of vectorization, while the row-store is not. Thus, when I run the same query with CPU optimizations turned on, I get the following result:
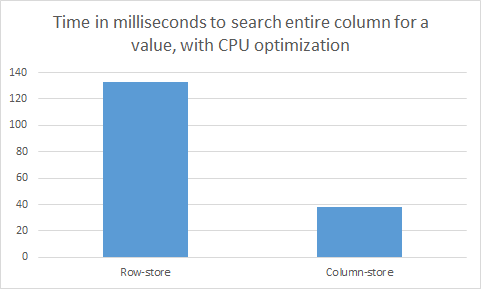
As can be seen, the EC2 processor appears to be vectorising 4 values per instruction, and therefore the column-store is 4 times faster than the row-store. However, the CPU still appears to be the bottleneck (if memory was the bottleneck, we would expect the column-store to be 6 times faster than the row-store).
We can thus conclude from this experiment that column-stores are still better than row-stores for attribute-limited, sequential scan queries like the one in our example and similar queries typically found in data analytics workloads. So indeed, it does not matter whether the data is stored on disk or in memory --- column-stores are a win for these types of workloads. However, the reason is totally different. When the table is stored on disk, the CPU is much faster than the bandwidth with which data can be transferred from disk to the CPU. Therefore, column-stores are a win because they require less data to be transferred for these workloads. On the other hand, when the table is stored in memory, the amount of data that needs to be transferred is less relevant. Instead, column-stores are a win because they are better suited to vectorized processing.
The reason why it is so important to understand the difference in bottleneck (even though the bottom line is the same) is that certain decisions for how to organize data into storage formats will look different depending on the bottleneck. Most notably, compression decisions will look very different. In particular, for data stored on disk, where the bandwidth of getting data from disk to CPU is the bottleneck, compression is almost always a good idea. When you compress data, the total size of the data is decreased, and therefore less data needs to be transferred. However, you may have to pay additional CPU processing costs to do the decompression upon arrival. But if CPU is not the bottleneck, this is a great tradeoff to make. On the other hand, if CPU is the bottleneck, such as our experiments above where the data was located in main memory, the additional CPU cost of decompression is only going to slow down the query.
Now we can understand some of the key differences between Apache Parquet/ORC and Apache Arrow. Parquet and ORC, since they are designed for disk-resident data, support high-ratio compression algorithms such as snappy (both), gzip (Parquet), and zlib (ORC) all of which typically require decompression before data processing (and the associated CPU costs). Meanwhile, Arrow, which is designed for memory-resident-data, does not support these algorithms. The only compression currently supported by Arrow is dictionary compression, a scheme that usually does not require decompression before data processing. For example, if you want to find a particular value in a data set, you can simply search for the associated dictionary-encoded value instead. I assume that the Arrow developers will eventually read my 2006 paper on compression in column-stores and expand their compression options to include other schemes which can be operated on directly (such as run-length-encoding and bit-vector compression). I also expect that they will read the X100 compression paper which includes schemes which can be decompressed using vectorized processing. Thus, I expect that Arrow will eventually support an expanded set of compression options beyond just dictionary compression. But it is far less likely that we will see heavier-weight schemes like gzip and snappy in the Apache Arrow library any time soon.
Another difference between optimizing for main memory and optimizing for disk is that the relative difference between random reads and sequential reads is much smaller for memory than for disk. For magnetic disk, a sequential read can be 2-3 orders of magnitude faster than a random read. However, for memory, the difference is usually less than an order of magnitude. In other words, it might take hundreds or even thousands of sequential reads on disk in order to amortize the cost of the original random read to get to the beginning of the sequence. But for main memory, it takes less than ten sequential reads to amortize the cost of the original random read. This enables the batch size of Apache Arrow data to be much smaller than batch sizes of disk-oriented storage formats. Apache Arrow actually fixes batches to be no more 64K records.
So to return back to the original question: do we really need a third column-store Apache project? I would say that there are fundamental differences between main-memory column-stores and disk-resident column-stores. Main-memory column-stores, like Arrow, need to be CPU optimized and focused on vectorized processing (Arrow aligns data to 64-byte boundaries for this reason) and low-overhead compression algorithms. Disk-resident column-stores need to be focused transfer-bandwidth and support higher-compression ratio algorithms. Therefore, it makes sense to keep Arrow and Parquet/ORC as separate projects, while also continuing to maintain tight integration.