The world wide web (WWW) has had an extraordinary impact
on our day-to-day lives. An enormous amount of information is
available to any participant at extremely low cost (usually this cost
is paid via one’s attention to advertisements). However, the interface
is fundamentally limited. A user must either have pre-existing
knowledge of the location of the needed information (e.g., the correct
URL), or use a search interface which generally attempts to
match words in a search query with the natural language found on
the web. It is totally impossible to query the entire Internet with
a single SQL query (or any other structured query language), and
even if you could, the data available on the WWW is not published
in a format which would be amenable to such queries. Even for those Websites that provide an API to access structured data, the data is typically provided in JSON format, which is orders of magnitude slower to process than native relational data formats, and usually non-interoperable with similar datasets provided by other Websites.
A small group of researchers and practitioners are today releasing a vision for a complete redesign of how we share structured data on the Internet. This vision is outlined in a 13 page paper that will be appearing in the data systems vision conference called CIDR that convenes next month. This vision includes a proposed architecture of a completely decentralized, ownerless platform for sharing structured data. This platform aims to enable a new WWW for structured data (e.g.,
data that fits in rows and columns of relational tables), with an
initial focus on IoT data. Anybody can publish structured data using their preferred schema, and they retain the ability to specify the permissions of that data. Some data will be published
with open access—in which case it will be queryable by any user of the platform. Other data will be published in encrypted form, in which
case only users with access to the decryption key may access query
results.
The platform is designed to make it easy for users to not only publish IoT (or any other types of structured) datasets, but even be rewarded every time the data that they publish is queried. The platform enables a SQL interface that supports querying the entire wealth of previously-published data. Questions such as:
“What was the maximum temperature reported in Palo Alto on June
21, 2008?” or “What was the difference in near accidents between
self-driving cars that used deep-learning model X vs. self-driving
cars that used deep-learning model Y?” or “How many cars passed
the toll bridge in the last hour?” or “How many malfunctions were
reported by a turbine of a particular model in all deployments in
the last year?” can all be expressed using clean and clearly specified
SQL queries over the data published in the the platform from many
different data sources.
The Internet of Things was chosen as the initial use-case for this vision since the data is machine-generated and usually requires less
cleaning than human-generated data. Furthermore, there are a limited
number of unique devices, with typically many instances of a
particular unique device. Each instance of a device (that is running
a particular software version) produces data according to an identical
schema (for a long period of time). This reduces the complexity
of the data integration problem. In many cases, device manufacturers
can also include digital signatures that are sent along with any
data generated by that device. These signatures can be used to verify
that the data was generated by a known manufacturer, thereby
reducing the ability of publishers to profit off of the contribution of
“fake data” to the platform.
As alluded to above, publishers receive a financial reward
every time the data that they contributed participates in a query
result. This reward accomplishes three important goals: (1) It motivates
data owners to contribute their data to the platform (2) It
motivates data owners to make their data public (since public data
will be queried more often than private data) (3) It motivates data
owners to use an existing schema to publish their data (instead of
creating a new one).
The first goal is an important departure from the WWW, where
data contributors are motivated by the fame and fortune that come
with bringing people directly to their website. Monetizing this web
traffic through ad revenue disincentivizes interoperability since providing
access to the data through a standardized API reduces the
data owner’s ability to serve advertisements. Instead, the proposed architecture enables
data contributors to monetize data through a SQL interface
that can answer queries from any source succinctly and directly. Making this data public, the second goal, increases the potential
for monetization.
The third goal is a critical one for structured data: the data integration
problem is best approached at the source—at the time that
the data is generated rather than at query time. The proposed architecture aims
to incentivize data integration prior to data publication by allowing
free market forces to generate consensus on a small number of economically
viable schemas per application domain. Of course, this incentivization
does not completely solve the data integration problem,
but we expect the platform to be useful for numerous application domains
even when large amounts of potentially relevant data must
be ignored at query time due to data integration challenges.
As a fully decentralized system, anybody can create an interface
to the data on the platform --- both for humans and for machines. We envision a typical human-oriented interface would
look like the following: users are presented with a faceted interface
that helps them to choose from a limited number of application
domains. Once the domain is chosen, the user is presented with another
faceted interface that enables the user to construct selection
predicates (to narrow the focus of the data that the user is interested
in within that domain). After this is complete, one of the schemas
from all of the registered schemas for that domain is selected based
on which datasets published using that schema contain the most
relevant data based on the user’s predicates. After the schema is
chosen, the interface aids the user in creating a static or streaming
SQL query over that schema. The entire set of data that was published using that schema, and for which the user who
issued the query has access to, is queried. The results are combined,
aggregated, and returned to the user. Machine interfaces would likely skip most of these steps, and instead query the platform directly in SQL (potentially after issuing some initial queries to access important metadata that enable the final SQL query to be formed).
The proposed architecture incorporates third-party contractors and
coordinators for storing and providing query access to data. Contractors
and coordinators act as middlemen between data publishers
and consumers. This allows publishers to meaningfully participate in the network without having to provide resources
for storage and processing of data. This also facilitates managing data
at the edge.
Despite making the system easier to use for publishers, the existence
of contractors and coordinators in the architecture present two
challenges: (1) How to incentivize them to participate, and (2) How
to preserve the integrity of data and query results when untrusted
and potentially malicious entities are involved in the storage and
processing. The published CIDR paper proposes an infrastructure to solve both these
challenges.
To overview these solutions briefly: Contractors and coordinators are incentivized similarly to publishers,
by a financial reward for every query they serve. Querying
the platform requires a small payment of tokens (a human-facing interface may serve advertisements to subsidize this token cost). These payment
tokens are shared between the publishers that contributed data that
was returned by the query, along with the contractors and coordinators
that were involved in processing that query.
The financial reward received per query incentivizes participation of contractors and coordinators in query processing. However,
it does not ensure that the participation is honest and correct query
results are returned. In fact, without safeguards, contractors and
coordinators can make more money by avoiding wasting local resources
on query processing, and instead returning half-baked answers
to query requests.
Indeed, one of the main obstacles to building decentralized database
systems like what we are proposing is how to secure the confidentiality, integrity,
and availability of data, query results, and payment/incentive processing
when the participants in the system are mutually distrustful
and no universally-trusted third party exists. Until
relatively recently, the security mechanisms necessary for building
such a system did not exist, were too inefficient, or were unable to
scale. Today, we believe recent advances in secure query processing,
blockchain, byzantine agreement, and trusted execution environments
put secure decentralized database systems within reach.
The proposed infrastructure uses a combination of these mechanisms
to secure data and computation within the system. For more details, please take a look at the CIDR paper!
I have a student, Gang Liao, who recently started building a prototype of the platform (research codebase at: https://github.com/DSLAM-UMD/P2PDB). Please contact us if you have some IoT data you can contribute our research prototype. Separate from this academic effort, there is also a company called AnyLog that has taken some of the ideas from the research paper and is building a non-fully decentralized version of the prototype.
Wednesday, December 18, 2019
Monday, October 7, 2019
Introducing SLOG: Cheating the low-latency vs. strict serializability tradeoff
This post provides an overview of a new technology from my lab that was recently published in VLDB 2019. In short: SLOG is a geographically distributed data store that guarantees both strict serializability and low latency (for both reads and writes). The first half of this post is written to convince you that it is impossible to achieve both strict serializability and low latency reads and writes, and gives examples of existing systems that achieve one or the other, but never both. The second half of the post describes how SLOG cheats this tradeoff and is the only system in research or industry that achieves both (in the common case).
Presenting stale state allows for low-latency interactions with the application around the world, but may lead to negative experiences by the end user. For example, observing stale state may result in users purchasing products that no longer exist, overdrawing balances from bank accounts, confusing discussion threading on social media, or reacting to incorrect stimuli in online multiplayer games.
Applications typically store state in some kind of “data store”. Some data stores guarantee “strong consistency” (such as strict consistency, atomic consistency, or linearizability, which I discussed in a previous post) that ensures that stale state will never be accessed. More specifically: any requests to access state on behalf of a client will reflect all state changes that occurred prior to that request. However, guaranteeing strong consistency may result in slower (high-latency) response times. In contrast, other data stores make reduced consistency guarantees and as a result, can achieve improved latency. In short, there is a tradeoff between consistency and latency: this is the ELC part of the PACELC theorem.
Separately, some systems provide support for transactions: groups of read and write requests that occur together as atomic units. Such systems typically provide “isolation” guarantees that prevent transactions from reading incomplete/temporary/incorrect data that were written by other concurrently running transactions. There are different levels of isolation guarantees, that I’ve discussed at length in previous posts (post 1, post 2, post 3), but the highest level is “serializability”, which guarantees that concurrent transactions are run in an equivalent fashion to how they would have been run if there were no other concurrently running transactions. In geo-distributed systems, where concurrently running transactions are running on physically separate machines that are potentially thousands of miles apart, serializability becomes harder to achieve. If fact, there exist proofs in the literature that show that there is a fundamental tradeoff between serializability and latency in geographically distributed systems.
Bottom line: there is a fundamental tradeoff between consistency and latency. And there is another fundamental tradeoff between serializability and latency.
Strict serializability includes perfect isolation (serializability) and consistency (linearizability) guarantees. If either one of those guarantees by itself is enough to incur a tradeoff with latency, then certainly the combination will necessarily require a latency tradeoff.
Indeed, a close examination of the commercial (and academic) data stores that guarantee strict serializability highlights this latency tradeoff. For example, Spanner (along with all the Spanner-derivative systems: Cloud Spanner, CockroachDB, and YugaByte) runs an agreement protocol (e.g. Paxos/Raft) as part every write to the data store in order to ensure that a majority of replicas agree to the write. This global coordination helps to ensure strict serializability, but increases the latency of each write. [Side note: neither CockroachDB nor YugaByte currently guarantee full strict serializability, but the reason for that is unrelated the discussion in this post, and discussed at length in several of my previous posts (post 1, post 2). The main point that is relevant for this post is that they inherit Spanner’s requirement to do an agreement protocol upon each write, which facilitates achieving a higher level of consistency than what would have been achieved if they did not inherit this functionality from Spanner.]
For example, if there are three copies of the data --- in North America, Europe, and Asia --- then every single write in Spanner and Spanner-derivative systems require agreement between at least two continents before it can complete. It is impossible to complete a write in less than 100 milliseconds in such deployments. Such high write latencies are unacceptable for most applications. Cloud Spanner, aware of this this latency problem that arises from the Spanner architecture, refuses to allow such “global” deployments. Rather, all writable copies of data must be within a 1000 mile radius (as of the time of publications of this post … see: https://cloud.google.com/spanner/docs/instances which currently says: “In general, the voting regions in a multi-region configuration are placed geographically close—less than a thousand miles apart—to form a low-latency quorum that enables fast writes (learn more).”). Spanner replicas outside of this 1000 mile radius must be read-only replicas that operate at a lag behind the quorum eligible copies. In summary, write latency is so poor in Spanner that they disable truly global deployments. [Side note: CockroachDB improves over Spanner by allowing truly global deployments and running Paxos only within geo-partitions, but as mentioned in the side note above, not with strict serializability.]
Amazon Aurora --- like Cloud Spanner --- explicitly disables strictly serializable global deployments. As of the time of this post, Aurora only guarantees serializable isolation for single-master deployments, and even then only on the primary instance. The read-only replicas operate at a maximum of “repeatable read” isolation.
Calvin and Calvin-derivative systems (such as Fauna, Streamy-db, and T-Part) typically have better write latency than Spanner-derivative systems (see my previous post on this subject for more details), but they still have to run an agreement protocol across the diameter of the deployment for every write transaction. The more geographically disperse the deployment, the longer the write latency.
In the research literature, papers like MDCC and TAPIR require at least one round trip across the geographic diameter of the deployment in order to guarantee strict serializability. Again: for truly global deployments, this leads to hundreds of milliseconds of latency.
In short: whether you focus on the theory, or whether you focus on the practice, it is seemingly impossible to achieve both strict serializability (for arbitrary transactions) and low latency reads and writes.
If the system can be certain that the next read after a write will occur from the same region of the world that originated the write, there is no need (from a strict serializability correctness perspective) to synchronously replicate the write to any other region. The next read will be served from the same near-by replica from which the write originated, and is guaranteed to see the most up to date value. The only reason to synchronously replicate to another region is for availability --- in case an entire region fails. Entire region failure is rare, but still important to handle in highly available systems. Some systems, such as Amazon Aurora, only synchronously replicate to a nearby region. This limits the latency effect from synchronous replication. Other systems, such as Spanner, run Paxos or Raft, which causes synchronous replication to a majority of regions in a deployment --- a much slower process. The main availability advantage of Paxos/Raft over replication to only nearby regions is to be able to remain (partially) available in the event of network partitions. However, Google themselves claim that network partitions are very rare, and have almost no effect on availability in practice. And Amazon clearly came to the same conclusion in their decision to avoid Paxos/Raft from the beginning.
To summarize, in practice: replication within a region and to near-by regions can achieve near identical levels of availability as Paxos/Raft, yet avoid the latency costs. And if there is locality in data access, there is no need to run synchronous replication of every write for any reason unrelated to availability. So in effect, for workloads with access locality, there is no strict serializability vs. low latency tradeoff. Simply serve reads from the same location as the most recent write to that same data item, and synchronously replicate writes only within a region and to near-by regions for availability.
Now, let’s drop the assumption of perfect locality. Those reads that initiate far from where that data item was last written must travel farther and thus necessarily take longer (i.e. high latency). If such reads are common, it is indeed impossible to achieve low latency and strict serializability at the same time. However, as long as the vast majority of reads initiate from locations near to where that item was last written, the vast majority of reads will achieve low latency. And writes also achieve low latency (since they are not synchronously replicated across the geographic diameter of the deployment). In short, low latency is achieved for the vast majority of reads and writes, without giving up strict serializability.
Where things get complicated are (1) How does the system which is processing a read know which region to send it to? In other words, how does any arbitrary region know which was the last region to write a data item? (2) What happens if a transaction needs to access multiple data items that were last written by different regions?
The solution to (1) is simpler than the solution to (2). For (1), each data item is assigned only one region at a time as its “home region”. Write to that data item can only occur at that home region. As the region locality of a data item shifts over time, an explicit hand-off process automatically occurs in which that data item is “rehoused” at a new region. Each region has a cache of the current house for each data item. If the cache is out of date for a particular read, the read will be initially sent to the wrong region, but that region will immediately forward the read request to the new home of that data item.
The solution to (2) is far more complicated. Getting such transactions to run correctly without unreasonably high latencies was a huge challenge. Our initial approach (not discussed in the paper we published) was to rehouse all data items accessed by a transaction to the same region prior to running it. Unfortunately, this approach interfered with the system’s ability to take advantage of the natural region locality in a workload (by forcing data items to be rehoused to non-natural locations) and made it nearly impossible to run transactions with overlapping access sets in parallel, which destroyed the throughput scalability of the system.
Instead, the paper we published uses a novel asynchronous replication algorithm that is designed to work with a deterministic execution framework based on our previous research on Calvin. This solution enables processing of “multi-home” transactions with no forced-rehousing, with half-round-trip cross-region latency. For example, let’s say that a transaction wants to read, modify, and write two data items: X and Y, where X is housed in the USA and Y is housed in Europe. All writes to X that occurred prior to this transaction are asynchronously sent from the USA to Europe, and (simultaneously) all writes to Y that occurred prior to this transaction are asynchronously sent from Europe to the USA. After this simple one-way communication across the contents is complete, each region then independently runs the read/modify/writes to both X and Y locally, and rely on determinism to ensure that they both are guaranteed to write the same exact values and come to the same commit/abort decision for the transaction without further communication.
Obviously there are many details that I’m leaving out of this short blog post. The reader is encouraged to look at the full paper for more details. But the final performance numbers are astonishingly good. SLOG is able to get the same throughput as state-of-the-art geographically replicated systems such as Calvin (which is an order of magnitude better than Spanner) while at the same time getting an order of magnitude better latency for most transactions, and equivalent latency to Paxos-based systems such as Calvin and Spanner for the remaining “multi-home” transactions.
An example of the latency improvement of SLOG over Paxos/Raft-based systems for a workload in which 90% of all reads initiate from the same region as where they were last written is shown in the figure below: [Experimental setup is described in the paper, and is run over a multi-continental geo-distributed deployment that includes locations on the west and east coasts of the US, and Europe.]
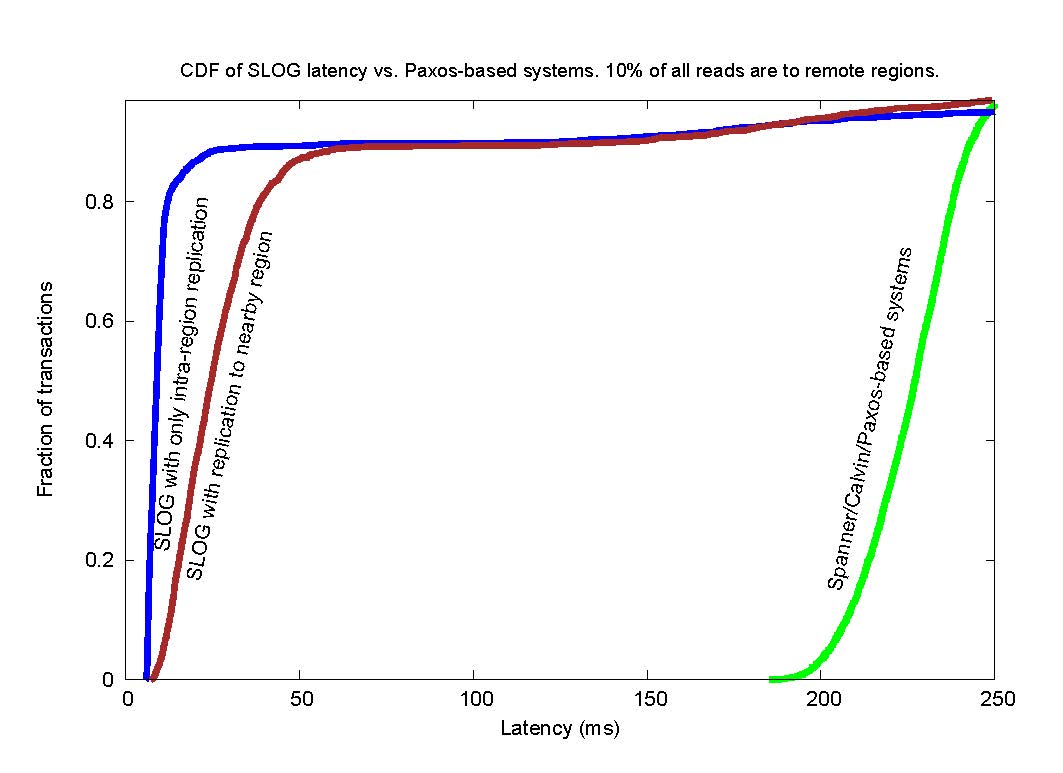
This figure shows two versions of SLOG --- one version that only replicates data within the same region, and one version that replicates also to a near-by region (to be robust to entire region failure). For the version of SLOG with only intra-region replication, the figure shows that 80% of transactions complete in less than 10 milliseconds, 90% less than 20 milliseconds, and the remaining transactions take no longer than round-trip Paxos latency across the diameter of the geographically dispersed deployment. Adding synchronous replication to near-by regions adds some latency, but only a small factor. In contrast, Paxos/Raft-based systems such as Spanner and Calvin take orders of magnitude longer latency to complete transactions for this benchmark (which is a simplified version of Figure 12 from the SLOG paper).
[This article includes a description of work that was funded by the NSF under grant IIS-1763797. Any opinions, findings, and conclusions or recommendations expressed in this article are those of Daniel Abadi and do not necessarily reflect the views of the National Science Foundation.]
The Strict Serializability vs. Low Latency Tradeoff
Modern applications span geographic borders with users located on any continent worldwide. Application state thus must be accessible anywhere. If application state never changes, it is possible for all users to interact with the global application with low latency. Application state is simply replicated to many locations around the world, and users can interact with their nearest replica. But for most applications, state changes over time: products get purchased, money is exchanged, users become linked, resources are consumed, etc. The problem is: sending messages across the world can take hundreds of milliseconds. There is thus a necessary delay before information about the state change travels to all parts of the world. In the meantime, applications have two choices: they can present stale, out-of-date state to the user, or they make the user wait until the correct, up-to-date state arrives.Presenting stale state allows for low-latency interactions with the application around the world, but may lead to negative experiences by the end user. For example, observing stale state may result in users purchasing products that no longer exist, overdrawing balances from bank accounts, confusing discussion threading on social media, or reacting to incorrect stimuli in online multiplayer games.
Applications typically store state in some kind of “data store”. Some data stores guarantee “strong consistency” (such as strict consistency, atomic consistency, or linearizability, which I discussed in a previous post) that ensures that stale state will never be accessed. More specifically: any requests to access state on behalf of a client will reflect all state changes that occurred prior to that request. However, guaranteeing strong consistency may result in slower (high-latency) response times. In contrast, other data stores make reduced consistency guarantees and as a result, can achieve improved latency. In short, there is a tradeoff between consistency and latency: this is the ELC part of the PACELC theorem.
Separately, some systems provide support for transactions: groups of read and write requests that occur together as atomic units. Such systems typically provide “isolation” guarantees that prevent transactions from reading incomplete/temporary/incorrect data that were written by other concurrently running transactions. There are different levels of isolation guarantees, that I’ve discussed at length in previous posts (post 1, post 2, post 3), but the highest level is “serializability”, which guarantees that concurrent transactions are run in an equivalent fashion to how they would have been run if there were no other concurrently running transactions. In geo-distributed systems, where concurrently running transactions are running on physically separate machines that are potentially thousands of miles apart, serializability becomes harder to achieve. If fact, there exist proofs in the literature that show that there is a fundamental tradeoff between serializability and latency in geographically distributed systems.
Bottom line: there is a fundamental tradeoff between consistency and latency. And there is another fundamental tradeoff between serializability and latency.
Strict serializability includes perfect isolation (serializability) and consistency (linearizability) guarantees. If either one of those guarantees by itself is enough to incur a tradeoff with latency, then certainly the combination will necessarily require a latency tradeoff.
Indeed, a close examination of the commercial (and academic) data stores that guarantee strict serializability highlights this latency tradeoff. For example, Spanner (along with all the Spanner-derivative systems: Cloud Spanner, CockroachDB, and YugaByte) runs an agreement protocol (e.g. Paxos/Raft) as part every write to the data store in order to ensure that a majority of replicas agree to the write. This global coordination helps to ensure strict serializability, but increases the latency of each write. [Side note: neither CockroachDB nor YugaByte currently guarantee full strict serializability, but the reason for that is unrelated the discussion in this post, and discussed at length in several of my previous posts (post 1, post 2). The main point that is relevant for this post is that they inherit Spanner’s requirement to do an agreement protocol upon each write, which facilitates achieving a higher level of consistency than what would have been achieved if they did not inherit this functionality from Spanner.]
For example, if there are three copies of the data --- in North America, Europe, and Asia --- then every single write in Spanner and Spanner-derivative systems require agreement between at least two continents before it can complete. It is impossible to complete a write in less than 100 milliseconds in such deployments. Such high write latencies are unacceptable for most applications. Cloud Spanner, aware of this this latency problem that arises from the Spanner architecture, refuses to allow such “global” deployments. Rather, all writable copies of data must be within a 1000 mile radius (as of the time of publications of this post … see: https://cloud.google.com/spanner/docs/instances which currently says: “In general, the voting regions in a multi-region configuration are placed geographically close—less than a thousand miles apart—to form a low-latency quorum that enables fast writes (learn more).”). Spanner replicas outside of this 1000 mile radius must be read-only replicas that operate at a lag behind the quorum eligible copies. In summary, write latency is so poor in Spanner that they disable truly global deployments. [Side note: CockroachDB improves over Spanner by allowing truly global deployments and running Paxos only within geo-partitions, but as mentioned in the side note above, not with strict serializability.]
Amazon Aurora --- like Cloud Spanner --- explicitly disables strictly serializable global deployments. As of the time of this post, Aurora only guarantees serializable isolation for single-master deployments, and even then only on the primary instance. The read-only replicas operate at a maximum of “repeatable read” isolation.
Calvin and Calvin-derivative systems (such as Fauna, Streamy-db, and T-Part) typically have better write latency than Spanner-derivative systems (see my previous post on this subject for more details), but they still have to run an agreement protocol across the diameter of the deployment for every write transaction. The more geographically disperse the deployment, the longer the write latency.
In the research literature, papers like MDCC and TAPIR require at least one round trip across the geographic diameter of the deployment in order to guarantee strict serializability. Again: for truly global deployments, this leads to hundreds of milliseconds of latency.
In short: whether you focus on the theory, or whether you focus on the practice, it is seemingly impossible to achieve both strict serializability (for arbitrary transactions) and low latency reads and writes.
How SLOG cheats Strict Serializability vs. Low Latency Tradeoff
Let’s say that a particular data item was written by a client in China. Where is the most likely location from which it will be accessed next? In theory, it could be accessed from anywhere. But in practice for most applications, (at least) 8 times out of 10, it will be accessed by a client in China. There is a natural locality in data access that existing strictly serializable systems have failed to exploit.If the system can be certain that the next read after a write will occur from the same region of the world that originated the write, there is no need (from a strict serializability correctness perspective) to synchronously replicate the write to any other region. The next read will be served from the same near-by replica from which the write originated, and is guaranteed to see the most up to date value. The only reason to synchronously replicate to another region is for availability --- in case an entire region fails. Entire region failure is rare, but still important to handle in highly available systems. Some systems, such as Amazon Aurora, only synchronously replicate to a nearby region. This limits the latency effect from synchronous replication. Other systems, such as Spanner, run Paxos or Raft, which causes synchronous replication to a majority of regions in a deployment --- a much slower process. The main availability advantage of Paxos/Raft over replication to only nearby regions is to be able to remain (partially) available in the event of network partitions. However, Google themselves claim that network partitions are very rare, and have almost no effect on availability in practice. And Amazon clearly came to the same conclusion in their decision to avoid Paxos/Raft from the beginning.
To summarize, in practice: replication within a region and to near-by regions can achieve near identical levels of availability as Paxos/Raft, yet avoid the latency costs. And if there is locality in data access, there is no need to run synchronous replication of every write for any reason unrelated to availability. So in effect, for workloads with access locality, there is no strict serializability vs. low latency tradeoff. Simply serve reads from the same location as the most recent write to that same data item, and synchronously replicate writes only within a region and to near-by regions for availability.
Now, let’s drop the assumption of perfect locality. Those reads that initiate far from where that data item was last written must travel farther and thus necessarily take longer (i.e. high latency). If such reads are common, it is indeed impossible to achieve low latency and strict serializability at the same time. However, as long as the vast majority of reads initiate from locations near to where that item was last written, the vast majority of reads will achieve low latency. And writes also achieve low latency (since they are not synchronously replicated across the geographic diameter of the deployment). In short, low latency is achieved for the vast majority of reads and writes, without giving up strict serializability.
Where things get complicated are (1) How does the system which is processing a read know which region to send it to? In other words, how does any arbitrary region know which was the last region to write a data item? (2) What happens if a transaction needs to access multiple data items that were last written by different regions?
The solution to (1) is simpler than the solution to (2). For (1), each data item is assigned only one region at a time as its “home region”. Write to that data item can only occur at that home region. As the region locality of a data item shifts over time, an explicit hand-off process automatically occurs in which that data item is “rehoused” at a new region. Each region has a cache of the current house for each data item. If the cache is out of date for a particular read, the read will be initially sent to the wrong region, but that region will immediately forward the read request to the new home of that data item.
The solution to (2) is far more complicated. Getting such transactions to run correctly without unreasonably high latencies was a huge challenge. Our initial approach (not discussed in the paper we published) was to rehouse all data items accessed by a transaction to the same region prior to running it. Unfortunately, this approach interfered with the system’s ability to take advantage of the natural region locality in a workload (by forcing data items to be rehoused to non-natural locations) and made it nearly impossible to run transactions with overlapping access sets in parallel, which destroyed the throughput scalability of the system.
Instead, the paper we published uses a novel asynchronous replication algorithm that is designed to work with a deterministic execution framework based on our previous research on Calvin. This solution enables processing of “multi-home” transactions with no forced-rehousing, with half-round-trip cross-region latency. For example, let’s say that a transaction wants to read, modify, and write two data items: X and Y, where X is housed in the USA and Y is housed in Europe. All writes to X that occurred prior to this transaction are asynchronously sent from the USA to Europe, and (simultaneously) all writes to Y that occurred prior to this transaction are asynchronously sent from Europe to the USA. After this simple one-way communication across the contents is complete, each region then independently runs the read/modify/writes to both X and Y locally, and rely on determinism to ensure that they both are guaranteed to write the same exact values and come to the same commit/abort decision for the transaction without further communication.
Obviously there are many details that I’m leaving out of this short blog post. The reader is encouraged to look at the full paper for more details. But the final performance numbers are astonishingly good. SLOG is able to get the same throughput as state-of-the-art geographically replicated systems such as Calvin (which is an order of magnitude better than Spanner) while at the same time getting an order of magnitude better latency for most transactions, and equivalent latency to Paxos-based systems such as Calvin and Spanner for the remaining “multi-home” transactions.
An example of the latency improvement of SLOG over Paxos/Raft-based systems for a workload in which 90% of all reads initiate from the same region as where they were last written is shown in the figure below: [Experimental setup is described in the paper, and is run over a multi-continental geo-distributed deployment that includes locations on the west and east coasts of the US, and Europe.]
This figure shows two versions of SLOG --- one version that only replicates data within the same region, and one version that replicates also to a near-by region (to be robust to entire region failure). For the version of SLOG with only intra-region replication, the figure shows that 80% of transactions complete in less than 10 milliseconds, 90% less than 20 milliseconds, and the remaining transactions take no longer than round-trip Paxos latency across the diameter of the geographically dispersed deployment. Adding synchronous replication to near-by regions adds some latency, but only a small factor. In contrast, Paxos/Raft-based systems such as Spanner and Calvin take orders of magnitude longer latency to complete transactions for this benchmark (which is a simplified version of Figure 12 from the SLOG paper).
Conclusion
By cheating the latency-tradeoff, SLOG is able to get average latencies on the order of 10 milliseconds for both reads and writes for the same geographically dispersed deployments that require hundreds of milliseconds in existing strictly serializable systems available today. SLOG does this without giving up strict serializability, without giving up throughput scalability, and without giving up availability (aside from the negligible availability difference relative to Paxos-based systems from not being as tolerant to network partitions). In short, by improving latency by an order of magnitude without giving up any other essential feature of the system, an argument can be made that SLOG is strictly better than the other strictly serializable systems in existence today.Friday, August 23, 2019
An explanation of the difference between Isolation levels vs. Consistency levels
(Editor's note: This post is cross-posted on Fauna's blog, where Daniel Abadi serves as an adviser. Fauna is is a serverless, cloud database system that is built using the Calvin scalable distributed data store technology from Daniel Abadi's research lab.)
In several recent posts, we discussed two ways to trade off correctness for performance in database systems. In particular, I wrote two posts (first one and second one) on the subject of isolation levels, and one post on the subject of consistency levels.
For many years, database users did not have to simultaneously understand the concept of isolation levels and consistency levels. Either a database system provided a correctness/performance tradeoff using isolation levels, or it provided a correctness/performance tradeoff using consistency levels, but never both. This resulted in a blurring of these concepts to the point that many people --- even experts in the field --- confuse isolation levels with consistency levels and vice versa. For example, this talk by a PhD student at Berkeley (incorrectly) refers to causal consistency as an “isolation level”. And this paper from well-known researchers at MIT and Harvard --- including a Turing Award laureate --- (incorrectly) call snapshot isolation and serializability “consistency” levels. I am confident that all these well-known researchers know the difference between isolation levels and consistency levels. However, as long as isolation and consistency could not be tuned within the same system, there has been little necessity for precision in the parlance around these terms.
In modern times, systems are being released that provide both a set of isolation levels and a set of consistency levels to choose from. Unfortunately, due to the historical failure in our community to be careful in our parlance, these new systems continue the legacy of blurring the distinction between isolation and consistency, which has resulted in “isolation levels” or “consistency levels” containing a mixture of isolation and consistency guarantees, and wide-spread confusion. Database users need more education on the difference between isolation levels and consistency levels and how they interact with each other in order to make an informed decision on how to trade off correctness for performance. This post is designed to be a resource for these types of decisions.
Background material
This post is designed to be a self-contained overview of the difference between isolation levels and consistency levels and how they interact with each other. You do not need to read my previous posts that I linked to above in order to read this post. Nonetheless, some of the definitions and fundamental concepts from those posts are important background material for understanding this post. To avoid making you read those previous posts, in this section, I will summarize the pertinent background material (but for more detail and elaboration, please see the previous posts).Database isolation refers to the ability of a database to allow a transaction to execute as if there are no other concurrently running transactions (even though in reality there can be a large number of concurrently running transactions). The overarching goal is to prevent reads and writes of temporary, incomplete, aborted, or otherwise incorrect data written by concurrent transactions.
If the application developer is able to ensure the correctness of their code when no other concurrent processes are running, a system that guarantees perfect isolation will ensure that the code remains correct even when there is other code running concurrently in the system that may read or write the same data. Thus, in order to achieve perfect isolation, the system must ensure that when transactions are running concurrently, the final state is equivalent to a state of the system that would exist if they were run serially. This perfect isolation level is called serializability.
One of our previous posts discussed some famous anomalies in application code that can occur at levels of isolation below serializability, and also some widely-used reduced isolation levels, of which the most notable are snapshot isolation and read committed. A detailed understanding of these anomalies and reduced isolation levels is not critical in order to understand the material we discuss below in this post.
Database consistency is defined in different ways depending on the context, but when a modern system offers multiple consistency levels, they define consistency in terms of the client view of the database. If two clients can see different states at the same point in time, we say that their view of the database is inconsistent (or, more euphemistically, operating at a “reduced consistency level”). Even if they see the same state, but that state does not reflect writes that are known to have committed previously, their view is inconsistent with the known state of the database.
We explained in our previous post that the notion of a consistency level originated by researchers of shared-memory multi-processor systems. The goal of the early work was to reason about how and when different threads of execution, which may be running concurrently and accessing overlapping sets of data in shared memory, should see the writes performed by each other. We gave a bunch of examples of consistency levels with examples using schedule figures similar to the one below, in which different threads of execution write and read data as time moves forward from left to right. In the figure below, we have four threads of execution: P1, P2, P3, and P4. P1 writes the value 5 to x, and thread P2 writes the value 10 to y after P1’s write to x completes. P3 and P4 read the new value (10) for y during overlapping periods of time. P3 and P4 then read x during overlapping periods of time. P3 starts slightly earlier and sees the old value, while P4 starts (and completes) later sees the new value.

To some degree, our example schedule is "consistent": although P3 and P4 read different values for x, since P4 initiated its read after P3, they can believe that the official value of x in the system did not change until a point in time in between these two read requests. P3 saw the new value of y (10) before reading the old value of x (0). Therefore, it believes that the write to y happened before the write to x. No thread observes a write ordering different from the write to y occurring before the write to x (P1 and P2 do not perform any reads, so they do not “see” anything, and P4 sees the new values of both x and y, and therefore did not see anything to contradict P3’s observation that the write to y happened before the write to x). Therefore, all threads can agree on a consistent, global sequential ordering of writes. This level of consistency is called sequential consistency.
Sequential consistency is a very high level of consistency, but it is not perfect. The reason why it is not perfect is that the globally observed write order contradicts reality. In reality, the write to x happens before the write to y. Furthermore, P3 sees a stale value for x: it reads the old value of x (0) long after the write of 5 to x has completed. This return of the non-current version of x is another example of contradicting reality. Perfect consistency (in this post, we are going to call linearizability “perfect” even though strict consistency has slightly stronger guarantees) ensures both: that every thread of execution observes the same write ordering AND that write ordering matches reality (if write A completes before write B starts, no thread will see the write to B happening before the write to A). This guarantee is also true for reads: if a write to A completes before a read of A begins, then the write of A will be visible to the subsequent read of A (assuming A was not overwritten by a different write request in the interim).
When expanding the traditional consistency diagrams such as the one from our example to a transactional model, we annotate each read and write request with the transaction identifier of the transaction that initiated each request. If each thread of execution can only process one transaction at a time, and transactions can not be processed by more than one thread of execution, then the traditional consistency diagrams need only be supplemented with rectangular boundaries indicating the start and end point of each transaction within a thread of execution, as shown in the figure below.

Once you include transactions in these consistency diagrams, the concept of database isolation must be considered (isolation is the I of ACID within the ACID set of guarantees for transactions). Depending on the isolation level, a write within a transaction may not become visible until the entire transaction is complete. Isolation guarantees thus place limitations on how and when writes become visible to threads of execution that read database state. Yet, consistency guarantees also specify how and when writes become visible! This conceptual overlap of isolation and consistency guarantees is the source of much confusion.
Ignorance is dangerous! You need to understand the difference between isolation guarantees and consistency guarantees. And you need to know what you are getting for both types of guarantees.
Let’s look at an example. The diagram below shows a system running two transactions in different threads of execution. Each transaction reads the current value of X, adds one to it, and writes it back out. In any serializable execution, the final value of X after running both transactions should be two higher than the initial value. But in this example, we have a system running at perfect, linearizable consistency, but the final value of X is only one higher than the initial value. Clearly, this is a correctness bug.
The basic problem is that historically, as we described above, consistency levels are only designed for single-operation actions. They generally do not model the possibility of a group of actions that commit or abort atomically. Therefore, they do not protect against the case where writes are performed only temporarily, but ultimately get rolled back if a transaction aborts. Furthermore, without explicit synchronization constructs, consistency levels do not protect against reads (on which subsequent writes in that same transaction depend) becoming immediately stale as a result of a concurrent write by a different process. (This latter problem is the problem that was shown in Figure 3).
The bottom line is that as soon as you have the concept of a transaction --- a group of read and write operations --- you need to have rules for what happens during the timeline between the first of the operations of the group and the last of the operations of the group. What operations by other threads of execution are allowed to occur during this time period between the first and last operation and which operations are not allowed? These set of rules are defined by isolation levels that I discussed previously. For example, serializable isolation states that the only concurrent operations that are allowed to occur are those which will not cause a visible change in database state relative to what the state would have been if there were no concurrent operations.
The bottom line: as soon as you allow transactions, you need isolation guarantees.
What about vice versa? Once you have isolation guarantees, do you need consistency guarantees?
Let’s look at another example. The diagram below shows a system running three transactions. In one thread of execution, a transaction runs (call it T1) that adds one to X (it was originally 4 and now it is 5). In the other thread of execution, a transaction runs (call it T2) that writes the current value of X to Y (5). After the transaction returns, a new transaction runs (call it T3) that reads the value of X and sees the old value (4). The result is entirely serializable (the equivalent serial order is T3 then T1 then T2). But it violates strict serializability and linearizability because it reorders T3 before T2 even though T3 started in real time after T2 completed. Furthermore, it violates sequential consistency because T2 and T3 are run in the same thread of execution, and under sequential consistency, the later transaction, T3, is not allowed to see an earlier value of X than the earlier transaction, T2. This could result in a bug in the application: many applications are unable to handle the phenomenon of database state going backwards in time across transactions --- and especially not within the same session.

Guarantees of isolation without any guarantees of consistency are not particularly helpful. As an extreme example: assume that a database started empty and then grows over time during the lifetime of an application. A system that guarantees perfect (serializable) isolation without any consistency guarantees could theoretically return the empty set (no results) for every single read-only transaction without violating its serializability guarantee. The serial order that the system is equivalent to is simply a serial order where the read-only transactions happen before the first write transaction. In essence, the serializability guarantee allows transactions to “go back in time” --- as long as the final result is equivalent to some serial order, the guarantee is upheld. Without some kind of consistency guarantee, there are no restrictions on which serial order it needs to be equivalent to.
In general, all of the time travel bugs that I discussed in a previous post in the context of serializability are possible at any isolation level. Isolation levels only specify what happens for concurrent transactions. If two transactions are not running at the same time, no isolation guarantee in the world will specify how they should be processed. They are already perfectly isolated from each other by virtue of not running concurrently with each other! This is what makes time travel correctness bugs possible at even the highest levels of isolation. If you want guarantees for nonconcurrent transactions: for example, you want to be sure that a later transaction reads the writes of an earlier transaction, you need consistency guarantees.
Many, but not all, consistency levels make real-time guarantees for nonconcurrent operations. For example, strict consistency and linearizable/atomic consistency both ensure that all nonconcurrent operations are ordered by real-time. Even lower consistency levels, such as sequential consistency and causal consistency make real time guarantees of operations within the same thread of execution.
So the bottom line is the following: once you have transactions with more than one operation, you need isolation guarantees. And if you need any kind of guarantee for non-concurrent transactions, you need consistency guarantees. Most of the time, if you are using a database system, you need both.
Therefore, as a database user, you need to figure out what you need in terms of isolation guarantees, and you also need to figure out what you need in terms of consistency guarantees. And if that wasn’t hard enough, you then need to figure out how to map what you think you need to the various options that your system gives you. This is where it gets really tricky, because many systems don’t view isolation and consistency as separate guarantees that can be intermixed arbitrarily. Rather, they only allow certain combinations of isolation guarantees and consistency guarantees, and give each combination a name. To make matters worse, the common industry practice is to call each name for a potential combination an “isolation level”, even though it is really a combination of an isolation level and a consistency level. We will give some examples in the next section.
“Isolation levels” that are really a mix of isolation and consistency guarantees
For my loyal readers that read everything I write, you might have been confused by my two posts on isolation guarantees when read together as a unit. In the earlier of these two posts, I claimed that serializability is the highest possible isolation level. Then, in the next post, I described a whole bunch of isolation levels there were seemingly “higher” or “more correct” --- “one-copy serializability”, “strong session serializability”, “strong write serializability”, “strong partition serializability”, and “strict serializability”.But now that we have gotten to this point in this post --- if you have understood what I’ve written so far, hopefully now the answer to why this is not a contradiction is obvious. Serializability is indeed the highest possible isolation level. All variations of serializability that we discussed --- one-copy serializability, strong session serializability, strong write serializability, strong partition serializability, and strict serializability have identical isolation guarantees: they all guarantee serializability. The only difference between these so called isolation levels are their consistency guarantees.
One-copy serializability guarantees sequential consistency where no thread of execution can process more than one transaction. Strong session serializability guarantees sequential consistency where each session corresponds to a separate thread of execution. Strong write serializability corresponds to a linearizability guarantee for write transactions, but only sequential consistency for read-only transactions. Strong partition serializability guarantees linearizable consistency within a partition, but only sequential consistency across partitions. And strict serializability guarantees linearizable consistency at all times for all reads and writes (across non-concurrent transactions).
The same method can be used to understand other so-called “isolation levels”. For example, the isolation levels of WEAK SNAPSHOT ISOLATION, STRONG SNAPSHOT ISOLATION, and STRONG SESSION SNAPSHOT ISOLATION are overviewed in this paper. All of these “isolation levels” make equivalent isolation guarantees: all guarantee snapshot isolation and are thus susceptible to write skew anomalies. The only difference is that STRONG SNAPSHOT ISOLATION guarantees linearizable consistency (if timestamps are based on real time) alongside SNAPSHOT ISOLATION’s imperfect isolation guarantee, while the other levels pair lower levels of consistency with snapshot isolation.
Conclusion
Database system vendors will continue to use single terms to describe a particular mixture of isolation levels and consistency levels. My recommendation is to avoid getting confused by these loaded definitions and break them apart before starting to reason about them. If you see an “isolation level” with three or more words, chances are, it is really an isolation level combined with a consistency level. Break apart the term into the component isolation and consistency guarantees, and then carefully consider each guarantee separately. What does your application require as far as isolation of concurrently running transactions? Does the isolation guarantee that the isolation level is giving you match your requirements? Furthermore, what does your application require as far as ordering of non-concurrent transactions? Does the consistency guarantee that you extracted from the complex term match your requirements?As a separate point, it is worth measuring the difference in performance you get between high isolation and consistency levels and lower ones. The quality of the architecture of the system can have a significant effect on the amount of performance drop for high isolation and consistency levels. Poorly designed systems will push you into choosing lower isolation and consistency levels by virtue of a dramatic performance drop if you choose higher levels. All systems will have some performance drop, but well-designed systems will observe a much less dramatic drop.
Thursday, July 25, 2019
Overview of Consistency Levels in Database Systems
Database systems typically give users the ability to trade off correctness for performance. We have spent the previous two posts in this series discussing one particular way to trade off correctness for performance: database isolation levels. In distributed systems, there is a whole other category for trading off correctness for performance: consistency levels. There are an increasing number of distributed database systems that are giving their users multiple different consistency levels to choose from, thereby allowing the user to specify which consistency guarantees are needed from the system for a particular application. Similar to isolation levels --- weaker consistency levels typically come with better performance, and thus come with the same types of temptations as reduced isolation levels.
In this post, we give a short tutorial on consistency levels --- explaining what they do, and how they work. Much of the existing literature and online discussion of consistency levels are done in the context of multi-processor or distributed systems that operate on a single data item at a time, without the concept of a “transaction”. In this post we give some direction for how to think about consistency levels in the context of ACID-compliant database systems.
The definition of consistency is fundamentally dependent on context. In general, consistency refers to the ability of a system to ensure that it complies (without fail) to a predefined set of rules. However, this set of rules changes based on context. For example, the C of ACID and the C of CAP both refer to consistency. However, the set of rules implied by these two contexts are totally different. In ACID, the rules refer to application-defined semantics. A system that guarantees the C of ACID ensures that processing a transaction does not violate referential integrity constraints, foreign-key constraints, and any other application-specific constraints (such as: “every user must have a name”). In contrast, the consistency C of CAP refers to the rules related to making a concurrent, distributed system appear like a single-threaded, centralized system. Reads at a particular point in time have only one possible result: they must reflect the most recent completed write (in real time) of that data item, no matter which server processed that write.
One point of confusion that we can eliminate at this point is that the phrase “consistency level” is not typically used in the context of ACID consistency. This is because the C of ACID is almost entirely the responsibility of the application developer --- only the developer can ensure that the code they place inside a transaction does not violate application semantics when it is run in isolation. ACID is really a misnomer --- really it should be AID, since only those three (atomicity, isolation, and durability) are in the realm of system guarantees. [Joe Hellerstein claims that he was taught that the C in ACID was only included to make an LSD pun, but acknowledges that this may be apocryphal.]
When we talk about consistency levels, we’re really referring the the C of CAP. In this context, perfect consistency --- usually referred to as “strict consistency” --- would imply that the system ensures that all reads reflect all previous writes --- no matter where those writes were performed. Any consistency level below “perfect” consistency enables situations to occur where a read does not return the most recent write of a data item. [Side note: the C of CAP in the original CAP paper refers to something called “atomic consistency” which is slightly weaker than strict consistency but still considered “perfect” for practical purposes. We’ll discuss the difference later in this post.]
Depending on how a particular system is architected, perfect consistency becomes easier or harder to achieve. In poorly designed systems, achieving perfection comes with a prohibitive performance and availability cost, and users of such systems are pushed to accept guarantees significantly short of perfection. However, even in well designed systems, there is often a non-trivial performance benefit achieved by accepting guarantees short of perfection.
The notion of a consistency level originated by researchers of shared-memory multi-processor systems. The goal of the early work was to reason about how and when different threads of execution, which may be running concurrently and accessing overlapping sets of data in shared memory, should see the writes performed by each other. As such, most of the initial work focused on reads and writes of individual data items, rather than at the level of groups of reads and writes within a transaction. We will begin our discussion using the same terminology as the original research and models, and then proceed to discuss how to apply these ideas to transactions.

In sequential consistency, all writes --- no matter which thread made the write, and no matter which data item was written to --- are globally ordered. Every single thread of execution must see the writes occurring in this order. For example, if one thread saw data X being updated to 5, and then later saw Y being updated to 10, every single thread must see the update of X happening before the update of Y. If any thread sees the new value of Y but the old value of X, sequential consistency would be violated. This example is shown in Figure 1. In this figure, time gets later as you move to the right in the figure, and there are 4 threads of execution: P1, P2, P3, and P4. Every thread (that reads X and Y) sees the update of X from 0 to 5 happening before the update of Y from 0 to 10. Threads: P1 and P2 write X and Y respectively, but do not read either one. Thread P3 sees the new value of X and subsequently sees the old value of Y. This is only possible if the update to X happened before the update to Y. Thread P4 only sees the new values of X and Y, so it does not see which one happened first. Thus, all threads agree that it is possible that the update of X happened before the update to Y. Contrast this to Figure 2, below, in which P3 and P4 see clearly different orders of the updates to X and Y --- P3 sees the new value of X (5) and subsequently the old value of Y (0), while P4 sees the new value of Y (10) and subsequently the old value of X (0). Figure 2 is thus not a sequentially consistent schedule.

In general, sequential consistency does not place any requirements on how to order the writes. In our example, the write to X happened in real time before the write to Y. Nonetheless, as long as every thread agrees to see the write to Y as happening before the write to X, sequential consistency allows the official history to be different that what occurred according to real time (the only restriction is that writes and reads originating from the same thread of execution cannot be reordered). See Figure 3 for an example of this.

In contrast to sequential consistency, strict consistency does place real time requirements on how to order the writes. It assumes that it is always possible to know what time it currently is with zero error --- i.e. that every thread of execution agree on the precise current time. The order of the writes in the sequential order must be equal to the real time that these writes were issued. Furthermore, every read operation must read the value of the most recent write in real time --- no matter which thread of execution initiated that write. In a distributed system (and even multi-processor single-server systems), it is impossible in practice to have global agreement on precise current time, which renders strict consistency to be mostly of theoretical interest.
None of Figures 1, 2, or 3 above satisfy strict consistency because they all contain either a read of x=0 or a read of y=0 after the value of x or y has been written to a new value. However, Figure 4 below satisfies strict consistency since all reads reflect the most recent write in real time:

In a distributed/replicated system, where writes and reads can originate anywhere, the highest level of consistency obtained in practice is linearizability (also known as “atomic consistency” which is what it is called in the CAP theorem). Linearizability is very similar to strict consistency: both are extensions of sequential consistency that impose real time constraints on writes. The difference is that the linearizability model acknowledges that there is a period of time that occurs between when an operation is submitted to the system, and when the system responds with an acknowledgement that it was completed. In a distributed system, the sending of the write request to the correct location(s) --- which may include replication --- can occur during this time period. A linearizability guarantee does not place any ordering constraints on operations that occur with overlapping start and end times. The only ordering constraint is for operations that do not overlap in time --- only in those cases does the earlier write have to be seen before the later write.

Figure 5 above shows an example of a schedule that is linearizable, but not strictly consistent. It is not strictly consistency since the read of X by P3 is initiated (and returns) slightly after the write of X by P1, but still sees the old value. Nonetheless, it is linearizable because this read of X by P3 and write of X by P1 overlap in time, and therefore linearizability does not require the read of X by P3 to see the result of the write of X by P1.
While linearizability and strict consistency are stronger than sequential consistency, sequential consistency is by itself a very high level of consistency, and there exist many consistency levels below it.
Causal consistency is a popular and useful consistency level that is slightly below sequential consistency. In sequential consistency, all writes must be globally ordered --- even if they are totally unrelated to each other. Causal consistency does not enforce orderings of unrelated writes. However, if a thread of execution performs a read of some data item (call it X) and then writes that data item or a different one (call it Y), it assumes that the subsequent write may have been caused by the read. Therefore, it enforces the order of X and Y --- specifically all threads of execution must observe the write of Y after the write of X.

As an example, compare Figure 6 (above) with Figure 2. In Figure 2, P3 saw the write to X happening before the write to Y, but P4 saw the write to Y happening before the write to X. This violates sequential consistency, but not causal consistency. However, in Figure 6, P2 read the write to X before performing the write to Y. That places a causal constraint between the write to X and Y --- Y must happen after X. Therefore, when P4 sees the write to Y without the write to X, causal consistency is violated.
Eventual consistency is even weaker --- even causally dependent writes may become visible out of order. For example, despite violating every other consistency guarantee that we have discussed so far, Figure 6 does not necessarily violate eventual consistency. The only guarantee in eventual consistency is that if there are no writes for a “long” period of time (where the definition of “long” is system dependent), every thread of execution will agree on the value of the last write. So as long as P4 eventually sees the new value of X (5) at some later point in time (not shown in Figure 6), then eventual consistency is maintained.
Strict consistency and linearizability/atomic consistency are typically thought of as “strong” consistency levels. In many cases, sequential consistency is also referred to as a strong consistency level. The key feature that each of these consistency levels share is that the state of the database goes through a universally agreed-upon sequence of state changes. This allows the realities of replication to be hidden to the end user. In essence, the view of the database to the user is that there is only one copy of the database that continuously makes state transitions in a forward direction. In contrast, weaker consistency levels (such as causal consistency and eventual consistency) allow different views of the database state to see different progression of steps in database state ---- a clear impossibility unless there is more than one copy of the database. Thus, for weaker levels of consistency, the application developer must be explicitly aware of the replicated nature of the data in the database, thereby increasing the complexity of development relative to strong consistency.
As we discussed above, consistency levels have historically been defined in terms of individual reads or writes of a data item. This makes the discussion of consistency levels hard to apply to the context of database systems in which groups of read and write operations occur together in atomic transactions. Indeed, both the research literature and vendor documentation (for those vendors that offer multiple consistency levels) are extremely confusing and do not take a uniform approach when it comes to applying consistency levels in the context of database systems.
I think that the simplest way to reason about consistency levels in the presence of database transactions is to make only minor adjustments to the consistency models we discussed earlier. We still view consistency as threads of execution sending read and write requests to a shared data store. The only difference is that we annotate each read and write request with the transaction identifier of the transaction that initiated each request. If each thread of execution can only process one transaction at a time, and transactions can not be processed by more than one thread of execution, then the traditional timeline consistency diagrams need only be supplemented with rectangular boundaries indicating the start and end point of each transaction within a thread of execution, as shown in the figure below.
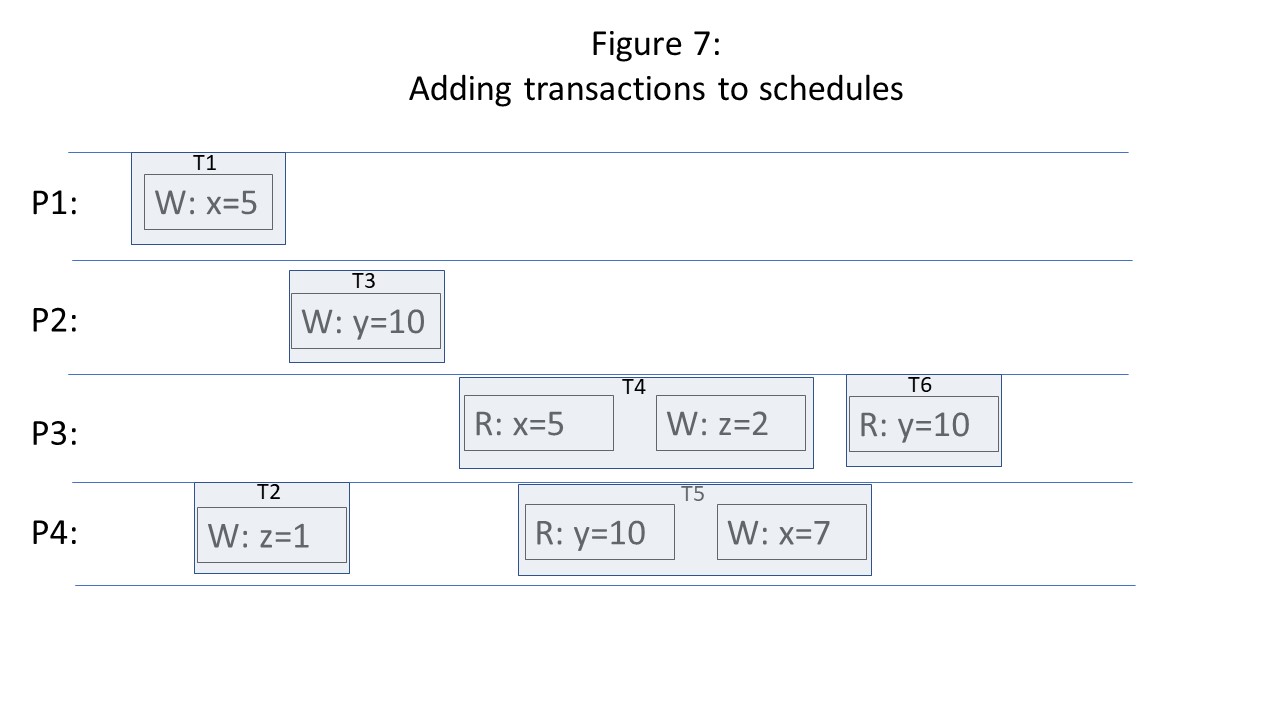
The presence of a transaction in a consistency diagram adds additional constraints corresponding to AID of ACID: all of the reads and writes within the transaction succeed or fail together (atomicity), they are isolated from other concurrently running transactions (the degree of isolation will depend on the isolation level), and writes of committed transactions will outlive all kinds of system failure (durability).
The atomicity and durability guarantees of transactions are pretty easy to cognitively separate from consistency guarantees, because they deal with fundamentally different concepts. The problem is isolation. Consistency guarantees specify how and when writes are visible to threads of execution that read database state. Isolation guarantees also place limitations on when writes become visible. This conceptual overlap of isolation and consistency guarantees is the source of much confusion. In the next post of this series I plan to give a tutorial for understanding the difference between isolation levels and consistency levels.
In this post, we give a short tutorial on consistency levels --- explaining what they do, and how they work. Much of the existing literature and online discussion of consistency levels are done in the context of multi-processor or distributed systems that operate on a single data item at a time, without the concept of a “transaction”. In this post we give some direction for how to think about consistency levels in the context of ACID-compliant database systems.
What is a consistency level?
One point of confusion that we can eliminate at this point is that the phrase “consistency level” is not typically used in the context of ACID consistency. This is because the C of ACID is almost entirely the responsibility of the application developer --- only the developer can ensure that the code they place inside a transaction does not violate application semantics when it is run in isolation. ACID is really a misnomer --- really it should be AID, since only those three (atomicity, isolation, and durability) are in the realm of system guarantees. [Joe Hellerstein claims that he was taught that the C in ACID was only included to make an LSD pun, but acknowledges that this may be apocryphal.]
When we talk about consistency levels, we’re really referring the the C of CAP. In this context, perfect consistency --- usually referred to as “strict consistency” --- would imply that the system ensures that all reads reflect all previous writes --- no matter where those writes were performed. Any consistency level below “perfect” consistency enables situations to occur where a read does not return the most recent write of a data item. [Side note: the C of CAP in the original CAP paper refers to something called “atomic consistency” which is slightly weaker than strict consistency but still considered “perfect” for practical purposes. We’ll discuss the difference later in this post.]
Depending on how a particular system is architected, perfect consistency becomes easier or harder to achieve. In poorly designed systems, achieving perfection comes with a prohibitive performance and availability cost, and users of such systems are pushed to accept guarantees significantly short of perfection. However, even in well designed systems, there is often a non-trivial performance benefit achieved by accepting guarantees short of perfection.
An overview of well-known consistency levels
In sequential consistency, all writes --- no matter which thread made the write, and no matter which data item was written to --- are globally ordered. Every single thread of execution must see the writes occurring in this order. For example, if one thread saw data X being updated to 5, and then later saw Y being updated to 10, every single thread must see the update of X happening before the update of Y. If any thread sees the new value of Y but the old value of X, sequential consistency would be violated. This example is shown in Figure 1. In this figure, time gets later as you move to the right in the figure, and there are 4 threads of execution: P1, P2, P3, and P4. Every thread (that reads X and Y) sees the update of X from 0 to 5 happening before the update of Y from 0 to 10. Threads: P1 and P2 write X and Y respectively, but do not read either one. Thread P3 sees the new value of X and subsequently sees the old value of Y. This is only possible if the update to X happened before the update to Y. Thread P4 only sees the new values of X and Y, so it does not see which one happened first. Thus, all threads agree that it is possible that the update of X happened before the update to Y. Contrast this to Figure 2, below, in which P3 and P4 see clearly different orders of the updates to X and Y --- P3 sees the new value of X (5) and subsequently the old value of Y (0), while P4 sees the new value of Y (10) and subsequently the old value of X (0). Figure 2 is thus not a sequentially consistent schedule.
In general, sequential consistency does not place any requirements on how to order the writes. In our example, the write to X happened in real time before the write to Y. Nonetheless, as long as every thread agrees to see the write to Y as happening before the write to X, sequential consistency allows the official history to be different that what occurred according to real time (the only restriction is that writes and reads originating from the same thread of execution cannot be reordered). See Figure 3 for an example of this.
In contrast to sequential consistency, strict consistency does place real time requirements on how to order the writes. It assumes that it is always possible to know what time it currently is with zero error --- i.e. that every thread of execution agree on the precise current time. The order of the writes in the sequential order must be equal to the real time that these writes were issued. Furthermore, every read operation must read the value of the most recent write in real time --- no matter which thread of execution initiated that write. In a distributed system (and even multi-processor single-server systems), it is impossible in practice to have global agreement on precise current time, which renders strict consistency to be mostly of theoretical interest.
None of Figures 1, 2, or 3 above satisfy strict consistency because they all contain either a read of x=0 or a read of y=0 after the value of x or y has been written to a new value. However, Figure 4 below satisfies strict consistency since all reads reflect the most recent write in real time:
In a distributed/replicated system, where writes and reads can originate anywhere, the highest level of consistency obtained in practice is linearizability (also known as “atomic consistency” which is what it is called in the CAP theorem). Linearizability is very similar to strict consistency: both are extensions of sequential consistency that impose real time constraints on writes. The difference is that the linearizability model acknowledges that there is a period of time that occurs between when an operation is submitted to the system, and when the system responds with an acknowledgement that it was completed. In a distributed system, the sending of the write request to the correct location(s) --- which may include replication --- can occur during this time period. A linearizability guarantee does not place any ordering constraints on operations that occur with overlapping start and end times. The only ordering constraint is for operations that do not overlap in time --- only in those cases does the earlier write have to be seen before the later write.
Figure 5 above shows an example of a schedule that is linearizable, but not strictly consistent. It is not strictly consistency since the read of X by P3 is initiated (and returns) slightly after the write of X by P1, but still sees the old value. Nonetheless, it is linearizable because this read of X by P3 and write of X by P1 overlap in time, and therefore linearizability does not require the read of X by P3 to see the result of the write of X by P1.
While linearizability and strict consistency are stronger than sequential consistency, sequential consistency is by itself a very high level of consistency, and there exist many consistency levels below it.
Causal consistency is a popular and useful consistency level that is slightly below sequential consistency. In sequential consistency, all writes must be globally ordered --- even if they are totally unrelated to each other. Causal consistency does not enforce orderings of unrelated writes. However, if a thread of execution performs a read of some data item (call it X) and then writes that data item or a different one (call it Y), it assumes that the subsequent write may have been caused by the read. Therefore, it enforces the order of X and Y --- specifically all threads of execution must observe the write of Y after the write of X.
As an example, compare Figure 6 (above) with Figure 2. In Figure 2, P3 saw the write to X happening before the write to Y, but P4 saw the write to Y happening before the write to X. This violates sequential consistency, but not causal consistency. However, in Figure 6, P2 read the write to X before performing the write to Y. That places a causal constraint between the write to X and Y --- Y must happen after X. Therefore, when P4 sees the write to Y without the write to X, causal consistency is violated.
Eventual consistency is even weaker --- even causally dependent writes may become visible out of order. For example, despite violating every other consistency guarantee that we have discussed so far, Figure 6 does not necessarily violate eventual consistency. The only guarantee in eventual consistency is that if there are no writes for a “long” period of time (where the definition of “long” is system dependent), every thread of execution will agree on the value of the last write. So as long as P4 eventually sees the new value of X (5) at some later point in time (not shown in Figure 6), then eventual consistency is maintained.
Strong consistency vs. Weak consistency
Strict consistency and linearizability/atomic consistency are typically thought of as “strong” consistency levels. In many cases, sequential consistency is also referred to as a strong consistency level. The key feature that each of these consistency levels share is that the state of the database goes through a universally agreed-upon sequence of state changes. This allows the realities of replication to be hidden to the end user. In essence, the view of the database to the user is that there is only one copy of the database that continuously makes state transitions in a forward direction. In contrast, weaker consistency levels (such as causal consistency and eventual consistency) allow different views of the database state to see different progression of steps in database state ---- a clear impossibility unless there is more than one copy of the database. Thus, for weaker levels of consistency, the application developer must be explicitly aware of the replicated nature of the data in the database, thereby increasing the complexity of development relative to strong consistency.
Transactions and consistency levels
As we discussed above, consistency levels have historically been defined in terms of individual reads or writes of a data item. This makes the discussion of consistency levels hard to apply to the context of database systems in which groups of read and write operations occur together in atomic transactions. Indeed, both the research literature and vendor documentation (for those vendors that offer multiple consistency levels) are extremely confusing and do not take a uniform approach when it comes to applying consistency levels in the context of database systems.
I think that the simplest way to reason about consistency levels in the presence of database transactions is to make only minor adjustments to the consistency models we discussed earlier. We still view consistency as threads of execution sending read and write requests to a shared data store. The only difference is that we annotate each read and write request with the transaction identifier of the transaction that initiated each request. If each thread of execution can only process one transaction at a time, and transactions can not be processed by more than one thread of execution, then the traditional timeline consistency diagrams need only be supplemented with rectangular boundaries indicating the start and end point of each transaction within a thread of execution, as shown in the figure below.
The presence of a transaction in a consistency diagram adds additional constraints corresponding to AID of ACID: all of the reads and writes within the transaction succeed or fail together (atomicity), they are isolated from other concurrently running transactions (the degree of isolation will depend on the isolation level), and writes of committed transactions will outlive all kinds of system failure (durability).
The atomicity and durability guarantees of transactions are pretty easy to cognitively separate from consistency guarantees, because they deal with fundamentally different concepts. The problem is isolation. Consistency guarantees specify how and when writes are visible to threads of execution that read database state. Isolation guarantees also place limitations on when writes become visible. This conceptual overlap of isolation and consistency guarantees is the source of much confusion. In the next post of this series I plan to give a tutorial for understanding the difference between isolation levels and consistency levels.
Monday, July 15, 2019
The dangers of conditional consistency guarantees
The ease of writing an application on top of infrastructure that guarantees consistency can not be overstated. It’s just so much easier to write an application when you can be sure that every read will return the most recent state of the data --- no matter where in the world writes to data state occur, and no matter what types of failure may occur.
Unfortunately, consistency in distributed systems comes at a cost. Other desirable system properties may be traded off in order to uphold a consistency guarantee. For example, it is well known (see the CAP theorem) that in the event of a network partition, it is impossible to guarantee both consistency and availability. One must be traded off for the other. Furthermore, in a system deployed across a wide geography, the laws of physics prevent the communication required to maintain consistency from happening instantaneously. This leads to the PACELC tradeoff: when there is a network partition (the P in PACELC), the system must decide how it will tradeoff availability (A) for consistency (C). Else (E) --- during normal operation of the system --- the system must decide how it will tradeoff latency (L) for consistency (C).
There are four points in the PACELC tradeoff space: (1) PA/EC (when there is a partition, choose availability; else, choose consistency), (2) PC/EC (choose consistency at all times), (3) PA/EL (prioritize availability and latency over consistency), and (4) PC/EL (when there is a partition, choose consistency; else, choose latency).
If you were to ask a student who just learned about the CAP theorem in a distributed systems class what guarantees they would want from a distributed system deployed for an application that needs 99.999% availability, the student would likely answer: “That’s easy! I would choose a system that prioritizes availability over consistency in the event of a network partition. But in the absence of a network partition, it is possible for a system to guarantee both availability and consistency, so I would want both those guarantees in the system I would deploy.”
This answer is natural and obvious. But at the same time, it is naive and incorrect.
The system that the student described would be a PA/EC system from PACELC --- a system that does not guarantee consistency during a network partition, but otherwise guarantees consistency. There are many applications that need several “nines” of availability. If the right PACELC system for those applications was PA/EC, then there would be many vendors competing with each other, attempting to sell the best PA/EC system. Yet in practice, the opposite is true --- it is extremely rare to find PA/EC systems in the wild. In fact, it took me several years until I came across the IMDG (in-memory data grid) market before I could find examples of real PA/EC systems.
The reason for this is that PA/EC systems are much less useful than one might initially expect. To understand why this is the case, one must understand the fundamental difference between a real guarantee and a conditional guarantee.
Of the three desirable properties that we’ve mentioned thus far as being desirable in a distributed system --- availability, consistency, and latency --- only one of them can ever be a real guarantee: consistency. No system will ever guarantee 100% availability, nor will any system guarantee that 100% of requests will complete within a particular latency bound. Such guarantees would be impossible to uphold. A “PA” system in PACELC prioritizes availability, but cannot guarantee 100% availability. Similarly, an “EL” system in PACELC prioritizes latency, but does not make any particular 100% guarantees.
In contrast, consistency is a real guarantee. Systems that guarantee consistency are actually capable of upholding the promise of 100% consistency, and many systems do in fact provide it.
Real guarantees form the foundation of the success of modern computing. Computers are extremely complex systems. Even a simple program must involve a large number of complex components --- from registers and logic gates to cache and memory to operating systems and security all the way up to the run time environment of the program. A simple “hello world” program ought to take weeks to develop. The reason why it doesn’t is because of the power of “abstraction” in computer science. Each level of a computer system builds on top of an underlying level that abstracts away the complex details of its implementation. Instead, the underlying level presents an interface to the higher level, and inviolable guarantees about what is returned through this interface.
For example, when a program reads from a particular place in memory, it can assume that it will see the data that was last written there. In reality, the processor inside a computer may choose to execute instructions within a program out of order. Furthermore, electric or magnetic interference may cause bits to spontaneously flip in memory. In practice, complicated solutions are used to detect and correct such bit corruption, including using redundant memory bits, additional circuitry, and error correcting codes. All of this is hidden to the higher level program that wants to read this location in memory. The higher level program assumes that it will receive the data that was most recently written to that location 100% of the time. [Side note: In theory, all of the error correcting logic in storage systems still cannot yield an actual 100% guarantee. However, the chances of a corrupted data value being returned to the end user is so infinitesimally small that this guarantee is still treated like 100% for all practical purposes.]
Imagine the extra complexity that would be involved in writing a program if you could not assume that instructions from a program are processed in the specified order, or the data in memory has not been corrupted. Almost every line of code that reads data from a variable would have to be surrounded by ‘if-statements’ that check for what might be corruption in that particular context and that specifies what should be done if the read appears to not be correct. This extra code would likely increase the development cycle for a program by one to two orders of magnitude!
For a program to be “bug-free”, this guarantee must be 100%. If a read returns the correct result 99% of the time, or even 99.99% or 99.9999% of the time, the above described ‘if-statements’ and conditional logic will still be necessary. Only if the program can assume that the correct result will always be returned can the extra conditional logic be avoided. Thus, from the perspective of the developer, there is an enormous difference between a complete guarantee and an incomplete guarantee. Within the space of incomplete guarantees, it is certainly the case that 99.9999% accuracy is better than 99% accuracy. But the big jump in complexity savings for the developer is the jump between anything less than 100% and a 100% guarantee.
This is why a PA/EC system has limited utility to an application developer. A PA/EC system is a system that guarantees consistency in all cases …. except when there is a network partition. In other words, a PA/EC makes a conditional guarantee of consistency: it guarantees consistency in all cases as long as a particular condition is met: that there is no network partition.
However, we just said that the big jump in complexity savings for the developer is a jump between anything less than 100% and a 100% guarantee. Any guarantee that comes with conditions that are out of the control of the developer (such as ensuring that there will never be a network partition), is not that helpful. The developer still has to write code to handle the cases where the guarantee is not upheld.
I am not arguing that all systems must guarantee consistency. I am only pointing out that there is a big difference in developer complexity between developing on top of a system that guarantees consistency fully, and one that guarantees consistency only under certain conditions. Without a full guarantee of consistency, there is a significant amount of extra effort required to ensure the absence of corner-case bugs that may emerge days, weeks, or even years after the application is first deployed.
We just explained that a PA system in PACELC results in a large amount of extra effort for the application developer, in order to ensure that the application remains bug-free even when inconsistent reads occur during a network partition. If so, during normal operation, where there is a tradeoff between consistency and latency, why choose consistency? All of the effort in building an application that does not break in the face of inconsistent reads has already been paid. Why not benefit from all that effort during normal operation and get better latency as well?
All of this suggests that application developers should decide whether they want to develop on top of a system that guarantees consistency or not. If they want consistency, they should deploy on top of a PC/EC system in PACELC --- i.e. a system that guarantees consistency 100% of the time. If they are willing to go to all of the extra effort to build on top of a system that does not guarantee consistency, they should be looking to get as many benefits as possible from this effort, and should deploy on top of PA/EL system, and thereby get better availability and latency properties (even if those properties do not come with guarantees).
As I pointed out in a previous post, when deploying within a single geographic region, the latency vs. consistency tradeoff is not significant. In such environments, there is not much difference between PA/EC and PA/EL systems. Since in-memory data grids are typically deployed in a single region, PA/EC became the standard PACELC option for the IMDG market.
Nonetheless, it is interesting to note how Hazelcast --- one of the most widely used IMDG implementations --- is moving away from the PA/EC default configuration and towards the more natural PC/EC and PA/EL pairings.
In 2017, I wrote an in-depth analysis of Hazelcast’s consistency and availability guarantees. At around the same time, Kyle Kingsbury published a linearizability analysis of Hazelcast using his Jepsen testing library. These analyses led to what CEO Greg Luck tells me was 3 person-years of effort to release the first PC/EC configuration option in Hazelcast.
A quick reminder about what Hazelcast does: Many Java programs store program state inside Java collections and data structures such as Queue, Map, or Multimap. As a program scales --- both in terms of the number of clients accessing data and in terms of the amount of data stored, these data structures may get too large to fit in memory on a single server. Hazelcast provides a distributed implementation of these popular data structures, thereby enabling programs that leverage them to scale. Java programs interact with Hazelcast identically to how they interacted with the local data Java structures. However, under the covers, Hazelcast is distributing and replicating them across a cluster of machines.
Hazelcast also provides distributed implementations of Java concurrency structures such as AtomicLong, AtomicReference, Lock. Using such structures without a consistency guarantee is downright dangerous. For example, in situations for which consistency is not upheld, it is possible for multiple different processes to acquire the same lock (concurrently) or for non-atomic actions to occur on supposedly atomic data structures. In other words, lack of consistency violates the fundamental premise of these backbone Java concurrency structures.
With a PC/EC configuration option, you can now deploy Hazelcast’s distributed version of these concurrency tools --- IAtomicLong, IAtomicReference, and ILock --- and get identical correctness guarantees relative to what they provide when being used by a regular single-server Java program.
Hazelcast’s PC/EC configuration performs distributed agreement on data structure state via the Raft consensus protocol. Raft is known for achieving strong availability. Even when a network partition occurs, the majority of servers can remain available (the consistency guarantee only requires that the minority partition must lose availability).
Separately from the consistency issue, another well-known problem with distributed implementations of lock data structures is liveness. A server can acquire the lock and then fail for an indefinite period of time while holding the lock. Meanwhile the rest of the distributed system remains alive, but unable to acquire the lock and make progress. Therefore, in practice, distributed locks typically include timeouts, in order to prevent servers that fail while holding the lock from causing the rest of the system to stall indefinitely. Unfortunately, as soon as it is possible for a lock to timeout, it is possible for a process to get timed out while holding the lock, and yet be temporarily unaware that the lock timed out. In such a scenario, it is possible for two different processes to concurrently believe they have the lock, and perform concurrent side-effects that the lock was designed to prevent. Hazelcast’s distributed lock implementation includes a fencing mechanism which enables downstream code --- code that is designed to be run while locks are being held --- to participate in the locking protocol and be able to distinguish which process is correct when multiple processes concurrently believe that they hold the lock.
As far as the PA/EL option in Hazelcast, they have recently added PN Counters --- a CRDT counter implementation that enables some correctness guarantees despite the potential for inconsistent reads. In particular, when there is no consistency guarantee, it is possible for a server to read a stale value of the counter. For example, process A may update the value of a counter from 4 to 5. Afterwards, process B sees the stale value of the counter (4) and also adds one to it (to get 5). In versions of Hazelcast prior to 3.10, the final value of the counter --- even after whatever event caused the inconsistency is resolved --- would be 5. In other words, one of the two increments of the counter would be lost. With PN Counters (introduced in Hazelcast 3.10), the counter state will eventually converge to the correct value (in this case --- 6 --- that reflects the value after two increments to an initial value of 4). PN Counters also support decrements of the counter (in addition to increments), and guarantees (1) read-your-own-writes and (2) monotonic reads in addition to (3) what I described above --- the eventual convergence of the counter value to the correct value.
Furthermore, inconsistent reads in Hazelcast prior to version 3.10 --- under PA/EC or PA/EL configurations --- could potentially result in duplicate IDs being generated. Hazelcast 3.10 introduced Flake ID generators which guarantee global unique IDs even in the absence of a global consistency guarantee.
PA/EC systems sound good in theory, but are not particularly useful in practice. Our one example of a real PA/EC system --- Hazelcast --- has spent the past 1.5 years introducing features that are designed for alternative PACELC configurations --- specifically PC/EC and PA/EL configurations. PC/EC and PA/EL configurations are a more natural cognitive fit for an application developer. Either the developer can be certain that the underlying system guarantees consistency in all cases (the PC/EC configuration) in which case the application code can be significantly simplified, or the system makes no guarantees about consistency at all (the PA/EL configuration) but promises high availability and low latency. CRDTs and globally unique IDs can still provide limited correctness guarantees despite the lack of consistency guarantees in PA/EL configurations.
Unfortunately, consistency in distributed systems comes at a cost. Other desirable system properties may be traded off in order to uphold a consistency guarantee. For example, it is well known (see the CAP theorem) that in the event of a network partition, it is impossible to guarantee both consistency and availability. One must be traded off for the other. Furthermore, in a system deployed across a wide geography, the laws of physics prevent the communication required to maintain consistency from happening instantaneously. This leads to the PACELC tradeoff: when there is a network partition (the P in PACELC), the system must decide how it will tradeoff availability (A) for consistency (C). Else (E) --- during normal operation of the system --- the system must decide how it will tradeoff latency (L) for consistency (C).
There are four points in the PACELC tradeoff space: (1) PA/EC (when there is a partition, choose availability; else, choose consistency), (2) PC/EC (choose consistency at all times), (3) PA/EL (prioritize availability and latency over consistency), and (4) PC/EL (when there is a partition, choose consistency; else, choose latency).
If you were to ask a student who just learned about the CAP theorem in a distributed systems class what guarantees they would want from a distributed system deployed for an application that needs 99.999% availability, the student would likely answer: “That’s easy! I would choose a system that prioritizes availability over consistency in the event of a network partition. But in the absence of a network partition, it is possible for a system to guarantee both availability and consistency, so I would want both those guarantees in the system I would deploy.”
This answer is natural and obvious. But at the same time, it is naive and incorrect.
The system that the student described would be a PA/EC system from PACELC --- a system that does not guarantee consistency during a network partition, but otherwise guarantees consistency. There are many applications that need several “nines” of availability. If the right PACELC system for those applications was PA/EC, then there would be many vendors competing with each other, attempting to sell the best PA/EC system. Yet in practice, the opposite is true --- it is extremely rare to find PA/EC systems in the wild. In fact, it took me several years until I came across the IMDG (in-memory data grid) market before I could find examples of real PA/EC systems.
The reason for this is that PA/EC systems are much less useful than one might initially expect. To understand why this is the case, one must understand the fundamental difference between a real guarantee and a conditional guarantee.
Real guarantees vs. conditional guarantees
Of the three desirable properties that we’ve mentioned thus far as being desirable in a distributed system --- availability, consistency, and latency --- only one of them can ever be a real guarantee: consistency. No system will ever guarantee 100% availability, nor will any system guarantee that 100% of requests will complete within a particular latency bound. Such guarantees would be impossible to uphold. A “PA” system in PACELC prioritizes availability, but cannot guarantee 100% availability. Similarly, an “EL” system in PACELC prioritizes latency, but does not make any particular 100% guarantees.
In contrast, consistency is a real guarantee. Systems that guarantee consistency are actually capable of upholding the promise of 100% consistency, and many systems do in fact provide it.
Real guarantees form the foundation of the success of modern computing. Computers are extremely complex systems. Even a simple program must involve a large number of complex components --- from registers and logic gates to cache and memory to operating systems and security all the way up to the run time environment of the program. A simple “hello world” program ought to take weeks to develop. The reason why it doesn’t is because of the power of “abstraction” in computer science. Each level of a computer system builds on top of an underlying level that abstracts away the complex details of its implementation. Instead, the underlying level presents an interface to the higher level, and inviolable guarantees about what is returned through this interface.
For example, when a program reads from a particular place in memory, it can assume that it will see the data that was last written there. In reality, the processor inside a computer may choose to execute instructions within a program out of order. Furthermore, electric or magnetic interference may cause bits to spontaneously flip in memory. In practice, complicated solutions are used to detect and correct such bit corruption, including using redundant memory bits, additional circuitry, and error correcting codes. All of this is hidden to the higher level program that wants to read this location in memory. The higher level program assumes that it will receive the data that was most recently written to that location 100% of the time. [Side note: In theory, all of the error correcting logic in storage systems still cannot yield an actual 100% guarantee. However, the chances of a corrupted data value being returned to the end user is so infinitesimally small that this guarantee is still treated like 100% for all practical purposes.]
Imagine the extra complexity that would be involved in writing a program if you could not assume that instructions from a program are processed in the specified order, or the data in memory has not been corrupted. Almost every line of code that reads data from a variable would have to be surrounded by ‘if-statements’ that check for what might be corruption in that particular context and that specifies what should be done if the read appears to not be correct. This extra code would likely increase the development cycle for a program by one to two orders of magnitude!
For a program to be “bug-free”, this guarantee must be 100%. If a read returns the correct result 99% of the time, or even 99.99% or 99.9999% of the time, the above described ‘if-statements’ and conditional logic will still be necessary. Only if the program can assume that the correct result will always be returned can the extra conditional logic be avoided. Thus, from the perspective of the developer, there is an enormous difference between a complete guarantee and an incomplete guarantee. Within the space of incomplete guarantees, it is certainly the case that 99.9999% accuracy is better than 99% accuracy. But the big jump in complexity savings for the developer is the jump between anything less than 100% and a 100% guarantee.
This is why a PA/EC system has limited utility to an application developer. A PA/EC system is a system that guarantees consistency in all cases …. except when there is a network partition. In other words, a PA/EC makes a conditional guarantee of consistency: it guarantees consistency in all cases as long as a particular condition is met: that there is no network partition.
However, we just said that the big jump in complexity savings for the developer is a jump between anything less than 100% and a 100% guarantee. Any guarantee that comes with conditions that are out of the control of the developer (such as ensuring that there will never be a network partition), is not that helpful. The developer still has to write code to handle the cases where the guarantee is not upheld.
I am not arguing that all systems must guarantee consistency. I am only pointing out that there is a big difference in developer complexity between developing on top of a system that guarantees consistency fully, and one that guarantees consistency only under certain conditions. Without a full guarantee of consistency, there is a significant amount of extra effort required to ensure the absence of corner-case bugs that may emerge days, weeks, or even years after the application is first deployed.
Conditional guarantees and PACELC
All of this suggests that application developers should decide whether they want to develop on top of a system that guarantees consistency or not. If they want consistency, they should deploy on top of a PC/EC system in PACELC --- i.e. a system that guarantees consistency 100% of the time. If they are willing to go to all of the extra effort to build on top of a system that does not guarantee consistency, they should be looking to get as many benefits as possible from this effort, and should deploy on top of PA/EL system, and thereby get better availability and latency properties (even if those properties do not come with guarantees).
New consistency guarantees in Hazelcast
Nonetheless, it is interesting to note how Hazelcast --- one of the most widely used IMDG implementations --- is moving away from the PA/EC default configuration and towards the more natural PC/EC and PA/EL pairings.
In 2017, I wrote an in-depth analysis of Hazelcast’s consistency and availability guarantees. At around the same time, Kyle Kingsbury published a linearizability analysis of Hazelcast using his Jepsen testing library. These analyses led to what CEO Greg Luck tells me was 3 person-years of effort to release the first PC/EC configuration option in Hazelcast.
A quick reminder about what Hazelcast does: Many Java programs store program state inside Java collections and data structures such as Queue, Map, or Multimap. As a program scales --- both in terms of the number of clients accessing data and in terms of the amount of data stored, these data structures may get too large to fit in memory on a single server. Hazelcast provides a distributed implementation of these popular data structures, thereby enabling programs that leverage them to scale. Java programs interact with Hazelcast identically to how they interacted with the local data Java structures. However, under the covers, Hazelcast is distributing and replicating them across a cluster of machines.
Hazelcast also provides distributed implementations of Java concurrency structures such as AtomicLong, AtomicReference, Lock. Using such structures without a consistency guarantee is downright dangerous. For example, in situations for which consistency is not upheld, it is possible for multiple different processes to acquire the same lock (concurrently) or for non-atomic actions to occur on supposedly atomic data structures. In other words, lack of consistency violates the fundamental premise of these backbone Java concurrency structures.
With a PC/EC configuration option, you can now deploy Hazelcast’s distributed version of these concurrency tools --- IAtomicLong, IAtomicReference, and ILock --- and get identical correctness guarantees relative to what they provide when being used by a regular single-server Java program.
Hazelcast’s PC/EC configuration performs distributed agreement on data structure state via the Raft consensus protocol. Raft is known for achieving strong availability. Even when a network partition occurs, the majority of servers can remain available (the consistency guarantee only requires that the minority partition must lose availability).
Separately from the consistency issue, another well-known problem with distributed implementations of lock data structures is liveness. A server can acquire the lock and then fail for an indefinite period of time while holding the lock. Meanwhile the rest of the distributed system remains alive, but unable to acquire the lock and make progress. Therefore, in practice, distributed locks typically include timeouts, in order to prevent servers that fail while holding the lock from causing the rest of the system to stall indefinitely. Unfortunately, as soon as it is possible for a lock to timeout, it is possible for a process to get timed out while holding the lock, and yet be temporarily unaware that the lock timed out. In such a scenario, it is possible for two different processes to concurrently believe they have the lock, and perform concurrent side-effects that the lock was designed to prevent. Hazelcast’s distributed lock implementation includes a fencing mechanism which enables downstream code --- code that is designed to be run while locks are being held --- to participate in the locking protocol and be able to distinguish which process is correct when multiple processes concurrently believe that they hold the lock.
As far as the PA/EL option in Hazelcast, they have recently added PN Counters --- a CRDT counter implementation that enables some correctness guarantees despite the potential for inconsistent reads. In particular, when there is no consistency guarantee, it is possible for a server to read a stale value of the counter. For example, process A may update the value of a counter from 4 to 5. Afterwards, process B sees the stale value of the counter (4) and also adds one to it (to get 5). In versions of Hazelcast prior to 3.10, the final value of the counter --- even after whatever event caused the inconsistency is resolved --- would be 5. In other words, one of the two increments of the counter would be lost. With PN Counters (introduced in Hazelcast 3.10), the counter state will eventually converge to the correct value (in this case --- 6 --- that reflects the value after two increments to an initial value of 4). PN Counters also support decrements of the counter (in addition to increments), and guarantees (1) read-your-own-writes and (2) monotonic reads in addition to (3) what I described above --- the eventual convergence of the counter value to the correct value.
Furthermore, inconsistent reads in Hazelcast prior to version 3.10 --- under PA/EC or PA/EL configurations --- could potentially result in duplicate IDs being generated. Hazelcast 3.10 introduced Flake ID generators which guarantee global unique IDs even in the absence of a global consistency guarantee.
Conclusion
Friday, June 28, 2019
Correctness Anomalies Under Serializable Isolation
Most database systems support multiple isolation levels that enable their users to trade off exposure to various types of application anomalies and bugs for (potentially small) increases in potential transaction concurrency. For decades, the highest level of “bug-free correctness” offered by commercial database systems was “SERIALIZABLE” isolation in which the database system runs transactions in parallel, but in a way that is equivalent to as if they were running one after the other. This isolation level was considered “perfect” because it enabled users that write code on top of a database system to avoid having to reason about bugs that could arise due to concurrency. As long as particular transaction code is correct in the sense that if nothing else is running at the same time, the transaction will take the current database state from one correct state to another correct state (where “correct” is defined as not violating any semantics of an application), then serializable isolation will guarantee that the presence of concurrently running transactions will not cause any kind of race conditions that could allow the database to get to an incorrect state. In other words, serializable isolation generally allows an application developer to avoid having to reason about concurrency, and only focus on making single-threaded code correct.
In the good old days of having a “database server” which is running on a single physical machine, serializable isolation was indeed sufficient, and database vendors never attempted to sell database software with stronger correctness guarantees than SERIALIZABLE. However, as distributed and replicated database systems have started to proliferate in the last few decades, anomalies and bugs have started to appear in applications even when running over a database system that guarantees serializable isolation. As a consequence, database system vendors started to release systems with stronger correctness guarantees than serializable isolation, which promise a lack of vulnerability to these newer anomalies. In this post, we will discuss several well known bugs and anomalies in serializable distributed database systems, and modern correctness guarantees that ensure avoidance of these anomalies.
What does “serializable” mean in a distributed/replicated system?
We defined “serializable isolation” above as a guarantee that even though a database system is allowed to run transactions in parallel, the final result is equivalent to as if they were running one after the other. In a replicated system, this guarantee must be strengthened in order to avoid the anomalies that would only occur at lower levels of isolation in non-replicated systems. For example, let’s say that the balance of Alice’s checking account ($50) is replicated so that the same value is stored in data centers in Europe and the United States. Many systems do not replicate data synchronously over such large distances. Rather, a transaction will complete at one region first, and its update to the database system may be replicated afterwards. If a withdrawal of $20 is made concurrently in the United States and Europe, the old balance is read ($50) in both places, $20 is removed from it, and the new balance ($30) is written back in both places and replicated to the other data center. This final balance is clearly incorrect ---- it should be $10 --- and was caused by concurrently executing transactions. But the truth is, the same outcome could happen if the transactions were serial (one after the other) as long as the replication is not included as part of the transaction (but rather happens afterwards). Therefore, a concurrency bug results despite equivalence to a serial order.
Rony Attar, Phil Bernstein, and Nathan Goodman expanded the concept of serializability in 1984 to define correctness in the context of replicated systems. The basic idea is that all the replicas of a data item behave like a single logical data item. When we say that a concurrent execution of transactions is “equivalent to processing them in a particular serial order”, this implies that whenever a data item is read, the value returned will be the most recent write to that data item by a previous transaction in the (equivalent) serial order --- no matter which copy was written by that write. In this context “most recent write” means the write by the closest (previous) transaction in that serial order. In our example above, either the withdrawal in Europe or the withdrawal in the US will be ordered first in the equivalent serial order. Whichever transaction is second --- when it reads the balance --- it must read the value written by the first transaction. Attar et. al. named this guarantee “one copy serializability” or “1SR”, because the isolation guarantee is equivalent to serializability in an unreplicated system with “one copy” of every data item.
Anomalies are possible under serializability; Anomalies are possible under one-copy serializability
We just stated that one-copy serializability in replicated systems is the identical isolation guarantee as serializability in unreplicated systems. There are many, many database systems that offer an isolation level called “serializability”, but very few (if any) replicated database systems that offer an isolation level called “one-copy serializability”. To understand why this is the case, we need to explain some challenges in writing bug-free programs on top of systems that “only” guarantee serializability.
A serializable system only guarantees that transactions will be processed in an equivalent way to some serial order. The serializability guarantee by itself doesn’t place any constraints on what this serial order is. In theory, one transaction can run and commit. Another transaction can come along --- a long period of time after the first one commits --- and be processed in such a way that the resulting equivalent serial order places the later transaction before the earlier one. In a sense, the later transaction “time travels” back in time, and is processed such that the final state of the database is equivalent to that transaction running prior to transactions that completed prior to when it began. A serializable system doesn’t prevent this. Nor does a one-copy serializable system. Nonetheless, in single-server systems, it is easy and convenient to prevent time-travel. Therefore, the vast majority of single-server systems that guarantee “serializability” also prevent time-travel. Indeed, it was so trivial to prevent time travel that most commercial serializable systems did not consider it notable enough to document their prevention of this behavior.
In contrast, in distributed and replicated systems, it is far less trivial to guarantee a lack of time travel, and many systems allow some forms of time travel in their transaction processing behavior.
The next few sections describe some forms of time-travel anomalies that occur in distributed and/or replicated systems, and the types of application bugs that they may cause. All of these anomalies are possible under a system that only guarantees one-copy serializability. Therefore, vendors typically document which of these anomalies they do and do not allow, thereby potentially guaranteeing a level of correctness higher than one-copy serializability. At the end of this post, we will classify different correctness guarantees and which time-travel anomalies they allow.
The immortal write
Let’s say the user of an application currently has a display name of “Daniel”, and decides to change it to “Danny”. He goes to the application interface, and changes his display name accordingly. He then reads his profile to ensure the change took effect, and confirms that it has. Two weeks later, he changes his mind again, and decides he wants to change his display name to “Danger”. He goes to the interface and changes his display name accordingly and was told that that change was successful. But when he performs a read on his profile, it still lists his name as “Danny”. He can go back and change his name a million times. Every time, he is told the change was successful, but the value of his display name in the system remains “Danny”.

In multi-master asynchronously replicated database systems, where writes are allowed to occur at either replica, it is possible for conflicting writes to occur across the replicas. In such a scenario, it is tempting to leverage time travel to create an immortal blind write, which enables straightforward conflict resolution without violating the serializability guarantee.
The stale read
The most common type of anomaly that appears in replicated systems but not in serializable single-server systems is the “stale read anomaly”. For example, Charlie has a bank account with $50 left in the account. He goes to an ATM and withdraws $50. Afterwards, he asks for a receipt with his current bank balance. The receipt (incorrectly) states that he has $50 left in his account (when, in actuality, he now has no money left). As a result, Charlie is left with an incorrect impression of how much money he has, and may make real life behavioral mistakes (for example, splurging on a new gadget) that he wouldn’t have done if he had the correct impression of the balance of his account. This anomaly happened as a result of a stale read: his account certainly used to have $50 in it. But when the ATM did a read request on the bank database to get his current balance, this read request did not reflect the write to his balance that happened a few seconds earlier when he withdrew money from his account.
The stale read anomaly is extremely common in asynchronously replicated database systems (such as read replicas in MySQL or Amazon Aurora). The write (the update to Charlie’s balance) gets directed to one copy, which is not immediately replicated to the other copy. If the read gets directed to the other copy before the new write has been replicated to it, it will see a stale value.

Stale reads do not violate serializability. The system is simply time travelling the read transaction to a point in time in the equivalent serial order of transactions before the new writes to this data item occur. Therefore, asynchronously replicated database systems can allow stale reads without giving up its serializability (or even one-copy serializability) guarantee.
In a single-server system, there’s little motivation to read anything aside from the most recent value of a data item. In contrast, in a replicated system, network delays from synchronous replication are time-consuming and expensive. It is therefore tempting to do replication asynchronously, since reads can occur from asynchronous read-only replicas without violating serializability (as long as the replicated data becomes visible in the same order as the original).
The causal reverse
In contrast to the stale read anomaly, the causal reverse anomaly can happen in any distributed database system and is independent of how replication is performed (synchronous or asynchronous). In the causal reverse anomaly, a later write which was caused by an earlier write, time-travels to a point in the serial order prior to the earlier write. In general, these two writes can be to totally different data items. Reads that occur in the serial order between these two writes may observe the “effect” without the “cause”, which can lead to application bugs.
For example, most banks do not exchange money between accounts in a single database transaction. Instead, money is removed from one account into bank-owned account in one transaction. A second transaction moves the money from the bank-owned account to the account intended as the destination for this transfer. The second transaction is caused by the first. If the first transaction didn’t succeed for any reason, the second transaction would never be issued.
Let’s say that $1,000,000 is being transferred from account A (which currently has $1,000,000 and will have $0 left after this transfer) to account B (which currently has $0, and will have $1,000,000 after the transfer). Let’s say that account A and account B are owned by the same entity, and this entity wishes to get a sizable loan that requires $2,000,000 as a down payment. In order to see if this customer is eligible for the loan, the lender issues a read transaction that reads the values of accounts A and B and takes the sum of the balance of those two accounts. If this read transaction occurs in the serial order before the transfer of $1,000,000 from A to B, a total of $1,000,000 will be observed across accounts. If this read transaction occurs after the transfer of $1,000,000 from A to B, a total of $1,000,000 will still be observed across accounts. If this read transaction occurs between the two transactions involved in transfer of $1,000,000 from A to B that we described above, a total of $0 will be observed across accounts. In all three possible cases, the entity will be (correctly) denied the loan due to lack of funds necessary for the down payment.

However, if a second transaction involved in the transfer (the one that adds $1,000,000 to account B) time-travels before the transaction that caused it to exist in the first place (the one that subtracts $1,000,000 from account A), it is possible for a read transaction that occurs between these two writes to (incorrectly) observe a balance across accounts of $2,000,000 and thereby allow the entity to secure the loan. Since the transfer was performed in two separate transactions, this example does not violate serializability. The equivalent serial order is: (1) the transaction that does the second part of the transfer (2) the read transaction and (3) the transaction that does the first part of the transfer. However, this example shows the potential for devastating bugs in application code code if causative transactions are allowed to time-travel to a point in time before their cause.
One example of a distributed database system that allows the causal reverse is CockroachDB (aka CRDB). CockroachDB partitions a database such that each partition commits writes and synchronously replicates data separately from other partitions. Each write receives a timestamp based on the local clock on one of the servers within that partition. In general, it is impossible to perfectly synchronize clocks across a large number of machines, so CockroachDB allows a maximum clock skew for which clocks across a deployment can differ. However, (unlike Google Spanner) CockroachDB does not wait for the maximum clock skew bound to pass before committing a transaction. Therefore, it is possible in CockroachDB for a transaction to commit, and a later transaction to come along (that writes data to a different partition), that was caused by the earlier one (that started after the earlier one finished), and still receive an earlier timestamp than the earlier transaction. This enables a read (in CockroachDB’s case, this read has to be sent to the system before the two write transactions) to potentially see the write of the later transaction, but not the earlier one.
In other words, if the bank example we’ve been discussing was implemented over CockroachDB, the entity wishing to secure the loan could simply repeatedly make the loan request and then transfer money between accounts A and B until the causal reverse anomaly shows up, and the loan is approved. Obviously, a well-written application should be able to detect the repeated loan requests and prevent this hack from occurring. But in general, it is hard to predict all possible hacks and write defensive application code to prevent them. Furthermore, banks are not usually able to recruit elite application programmers, which leads to some mind-boggling vulnerabilities in real-world applications.
Avoiding time travel anomalies
All the anomalies that we’ve discussed so far --- the immortal write, the stale read, and the causal reverse --- all exploit the permissibility of time travel in the serializability guarantee, and thereby introduce bugs in application code. To avoid these bugs, the system needs to guarantee that transactions are not allowed to travel in time, in addition to guaranteeing serializability. As we mentioned above, single-server systems generally make this time-travel guarantee without advertising it, since the implementation of this guarantee is trivial on a single-server. In distributed and replicated database systems, this additional guarantee of “no time travel” on top of the other serializability guarantees is non-trivial, but has nonetheless been accomplished by several systems such as FaunaDB/Calvin, FoundationDB, and Spanner. This high level of correctness is called strict serializability.
Strict serializability makes all of the guarantees of one-copy serializability that we discussed above. In addition, it guarantees that if a transaction X completed before transaction Y started (in real time) then X will be placed before Y in the serial order that the system guarantees equivalence to.
Classification of serializable systems
Systems that guarantee strict serializability eliminate all types of time travel anomalies. At the other end of the spectrum, systems that guarantee “only” one-copy serializability are vulnerable to all of the anomalies that we’ve discussed in this post (even though they are immune to the isolation anomalies we discussed in a previous post). There also exist systems that guarantee a version of serializability between these two extremes. One example are “strong session serializable” systems that guarantee strict serializability of transactions within the same session, but otherwise only one-copy serializability. Another example are "strong write serializable" systems that guarantee strict serializability for all transactions that insert or update data, but only one-copy serializability for read-only transactions. This isolation level is commonly implemented by read-only replica systems where all update transactions go to the master replica which processes them with strict serializability. These updates are asynchronously replicated to read-only replicas in the order they were processed at the master. Reads from the replicas may be stale, but they are still serializable. A third class of systems are "strong partition serializable" systems that guarantee strict serializability only on a per-partition basis. Data is divided into a number of disjoint partitions. Within each partition, transactions that access data within that partition are guaranteed to be strictly serializable. But otherwise, the system only guarantees one-copy serializability. This isolation level can be implemented by synchronously replicating writes within a partition, but avoiding coordination across partitions for disjoint writes (we explained above that CockroachDB is member of this class). Now that we have given names to these different levels of serializability, we can summarize the anomalies to which they are vulnerable with a simple chart:
System Guarantee
|
Immortal write
|
Stale read
|
Causal reverse
|
ONE COPY SERIALIZABLE
|
Possible
|
Possible
|
Possible
|
STRONG SESSION SERIALIZABLE
|
Possible (but not within same session)
|
Possible (but not within same session)
|
Possible (but not within same session)
|
STRONG WRITE SERIALIZABLE
|
Not Possible
|
Possible
|
Not Possible
|
STRONG PARTITION SERIALIZABLE
|
Not Possible
|
Not Possible
|
Possible
|
STRICT SERIALIZABLE
|
Not Possible
|
Not Possible
|
Not Possible
|
For readers who read my previous post on isolation levels, we can combine the isolation anomalies from that post with the time travel anomalies from this post to get a single table with all the anomalies we’ve discussed across the two posts:
System Guarantee
|
Dirty read
|
Non-repeatable read
|
Phantom Read
|
Write Skew
|
Immortal write
|
Stale read
|
Causal reverse
|
READ UNCOMMITTED
|
Possible
|
Possible
|
Possible
|
Possible
|
Possible
|
Possible
|
Possible
|
READ COMMITTED
|
Not Possible
|
Possible
|
Possible
|
Possible
|
Possible
|
Possible
|
Possible
|
REPEATABLE READ
|
Not Possible
|
Not Possible
|
Possible
|
Possible
|
Possible
|
Possible
|
Possible
|
SNAPSHOT ISOLATION
|
Not Possible
|
Not Possible
|
Not Possible
|
Possible
|
Possible
|
Possible
|
Possible
|
SERIALIZABLE / ONE COPY SERIALIZABLE / STRONG SESSION SERIALIZABLE
|
Not Possible
|
Not Possible
|
Not Possible
|
Not Possible
|
Possible
|
Possible
|
Possible
|
STRONG WRITE SERIALIZABLE
|
Not Possible
|
Not Possible
|
Not Possible
|
Not Possible
|
Not Possible
|
Possible
|
Not Possible
|
STRONG PARTITION SERIALIZABLE
|
Not Possible
|
Not Possible
|
Not Possible
|
Not Possible
|
Not Possible
|
Not Possible
|
Possible
|
STRICT SERIALIZABLE
|
Not Possible
|
Not Possible
|
Not Possible
|
Not Possible
|
Not Possible
|
Not Possible
|
Not Possible
|
Subscribe to:
Posts (Atom)