In several recent posts, we discussed two ways to trade off correctness for performance in database systems. In particular, I wrote two posts (
first one and
second one) on the subject of isolation levels, and one
post on the subject of consistency levels.
For many years, database users did not have to simultaneously understand the concept of isolation levels and consistency levels. Either a database system provided a correctness/performance tradeoff using isolation levels, or it provided a correctness/performance tradeoff using consistency levels, but never both. This resulted in a blurring of these concepts to the point that many people --- even experts in the field --- confuse isolation levels with consistency levels and vice versa. For example,
this talk by a PhD student at Berkeley (incorrectly) refers to causal consistency as an “isolation level”. And
this paper from well-known researchers at MIT and Harvard --- including a Turing Award laureate --- (incorrectly) call snapshot isolation and serializability “consistency” levels. I am confident that all these well-known researchers know the difference between isolation levels and consistency levels. However, as long as isolation and consistency could not be tuned within the same system, there has been little necessity for precision in the parlance around these terms.
In modern times, systems are being released that provide both a set of isolation levels and a set of consistency levels to choose from. Unfortunately, due to the historical failure in our community to be careful in our parlance, these new systems continue the legacy of blurring the distinction between isolation and consistency, which has resulted in “isolation levels” or “consistency levels” containing a mixture of isolation and consistency guarantees, and wide-spread confusion. Database users need more education on the difference between isolation levels and consistency levels and how they interact with each other in order to make an informed decision on how to trade off correctness for performance. This post is designed to be a resource for these types of decisions.
Background material
This post is designed to be a self-contained overview of the difference between isolation levels and consistency levels and how they interact with each other. You do not need to read my previous posts that I linked to above in order to read this post. Nonetheless, some of the definitions and fundamental concepts from those posts are important background material for understanding this post. To avoid making you read those previous posts, in this section, I will summarize the pertinent background material (but for more detail and elaboration, please see the previous posts).
Database isolation refers to the ability of a database to allow a transaction to execute as if there are no other concurrently running transactions (even though in reality there can be a large number of concurrently running transactions). The overarching goal is to prevent reads and writes of temporary, incomplete, aborted, or otherwise incorrect data written by concurrent transactions.
If the application developer is able to ensure the correctness of their code when no other concurrent processes are running, a system that guarantees
perfect isolation will ensure that the code remains correct even when there is other code running concurrently in the system that may read or write the same data. Thus, in order to achieve perfect isolation, the system must ensure that when transactions are running concurrently, the final state is equivalent to a state of the system that would exist if they were run serially. This perfect isolation level is called
serializability.
One of our previous posts
discussed some famous anomalies in application code that can occur at levels of isolation below serializability, and also some
widely-used reduced isolation levels, of which the most notable are snapshot isolation and read committed. A detailed understanding of these anomalies and reduced isolation levels is not critical in order to understand the material we discuss below in this post.
Database consistency is defined in
different ways depending on the context, but when a modern system offers multiple
consistency levels, they define consistency in terms of the client view of the database. If two clients can see different states at the same point in time, we say that their view of the database is
inconsistent (or, more euphemistically, operating at a “
reduced consistency level”). Even if they see the same state, but that state does not reflect writes that are known to have committed previously, their view is inconsistent with the known state of the database.
We explained
in our previous post that the notion of a
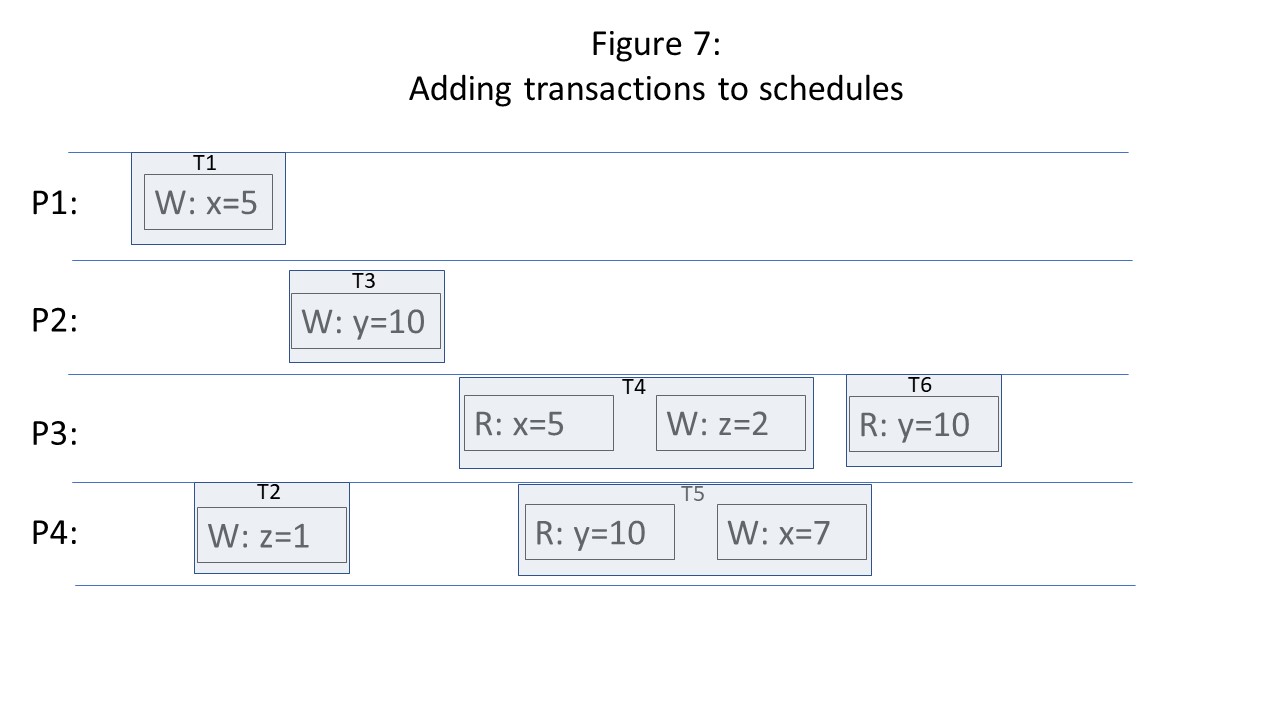
consistency level originated by researchers of shared-memory multi-processor systems. The goal of the early work was to reason about how and when different threads of execution, which may be running concurrently and accessing overlapping sets of data in shared memory, should see the writes performed by each other. We gave a bunch of examples of consistency levels with examples using schedule figures similar to the one below, in which different threads of execution write and read data as time moves forward from left to right. In the figure below, we have four threads of execution: P1, P2, P3, and P4. P1 writes the value 5 to x, and thread P2 writes the value 10 to y after P1’s write to x completes. P3 and P4 read the new value (10) for y during overlapping periods of time. P3 and P4 then read x during overlapping periods of time. P3 starts slightly earlier and sees the old value, while P4 starts (and completes) later sees the new value.

To some degree, our example schedule is "consistent": although P3 and P4 read different values for x, since P4 initiated its read after P3, they can believe that the official value of x in the system did not change until a point in time in between these two read requests. P3 saw the new value of y (10) before reading the old value of x (0). Therefore, it believes that the write to y happened before the write to x. No thread observes a write ordering different from the write to y occurring before the write to x (P1 and P2 do not perform any reads, so they do not “see” anything, and P4 sees the new values of both x and y, and therefore did not see anything to contradict P3’s observation that the write to y happened before the write to x). Therefore, all threads can agree on a consistent, global sequential ordering of writes. This level of consistency is called
sequential consistency.
Sequential consistency is a very high level of consistency, but it is not perfect. The reason why it is not perfect is that the globally observed write order contradicts reality. In reality, the write to x happens before the write to y. Furthermore, P3 sees a stale value for x: it reads the old value of x (0) long after the write of 5 to x has completed. This return of the non-current version of x is another example of contradicting reality. Perfect consistency (in this post, we are going to call
linearizability “perfect” even though
strict consistency has slightly stronger guarantees) ensures both: that every thread of execution observes the same write ordering AND that write ordering matches reality (if write A completes before write B starts, no thread will see the write to B happening before the write to A). This guarantee is also true for reads: if a write to A completes before a read of A begins, then the write of A will be visible to the subsequent read of A (assuming A was not overwritten by a different write request in the interim).
When expanding the traditional consistency diagrams such as the one from our example to a transactional model, we annotate each read and write request with the transaction identifier of the transaction that initiated each request. If each thread of execution can only process one transaction at a time, and transactions can not be processed by more than one thread of execution, then the traditional consistency diagrams need only be supplemented with rectangular boundaries indicating the start and end point of each transaction within a thread of execution, as shown in the figure below.

Once you include transactions in these consistency diagrams, the concept of database isolation must be considered (isolation is the I of ACID within the ACID set of guarantees for transactions). Depending on the isolation level, a write within a transaction may not become visible until the entire transaction is complete. Isolation guarantees thus place limitations on how and when writes become visible to threads of execution that read database state. Yet, consistency guarantees also specify how and when writes become visible! This conceptual overlap of isolation and consistency guarantees is the source of much confusion.
Ignorance is dangerous! You need to understand the difference between isolation guarantees and consistency guarantees. And you need to know what you are getting for both types of guarantees.
Let’s look at an example. The diagram below shows a system running two transactions in different threads of execution. Each transaction reads the current value of X, adds one to it, and writes it back out. In any serializable execution, the final value of X after running both transactions should be two higher than the initial value. But in this example, we have a system running at perfect, linearizable consistency, but the final value of X is only one higher than the initial value. Clearly, this is a correctness bug.

The basic problem is that historically, as we described above, consistency levels are only designed for single-operation actions. They generally do not model the possibility of a group of actions that commit or abort atomically. Therefore, they do not protect against the case where writes are performed only temporarily, but ultimately get rolled back if a transaction aborts. Furthermore, without explicit synchronization constructs, consistency levels do not protect against reads (on which subsequent writes in that same transaction depend) becoming immediately stale as a result of a concurrent write by a different process. (This latter problem is the problem that was shown in Figure 3).
The bottom line is that as soon as you have the concept of a transaction --- a group of read and write operations --- you need to have rules for what happens during the timeline between the first of the operations of the group and the last of the operations of the group. What operations by other threads of execution are allowed to occur during this time period between the first and last operation and which operations are not allowed? These set of rules are defined by isolation levels that
I discussed previously. For example, serializable isolation states that the only concurrent operations that are allowed to occur are those which will not cause a visible change in database state relative to what the state would have been if there were no concurrent operations.
The bottom line: as soon as you allow transactions, you need isolation guarantees.
What about vice versa? Once you have isolation guarantees, do you need consistency guarantees?
Let’s look at another example. The diagram below shows a system running three transactions. In one thread of execution, a transaction runs (call it T1) that adds one to X (it was originally 4 and now it is 5). In the other thread of execution, a transaction runs (call it T2) that writes the current value of X to Y (5). After the transaction returns, a new transaction runs (call it T3) that reads the value of X and sees the old value (4). The result is entirely serializable (the equivalent serial order is T3 then T1 then T2). But it violates strict serializability and linearizability because it reorders T3 before T2 even though T3 started in real time after T2 completed. Furthermore, it violates sequential consistency because T2 and T3 are run in the same thread of execution, and under sequential consistency, the later transaction, T3, is not allowed to see an earlier value of X than the earlier transaction, T2. This could result in a bug in the application: many applications are unable to handle the phenomenon of database state going backwards in time across transactions --- and especially not within the same session.

Guarantees of isolation without any guarantees of consistency are not particularly helpful. As an extreme example: assume that a database started empty and then grows over time during the lifetime of an application. A system that guarantees perfect (serializable) isolation without any consistency guarantees could theoretically return the empty set (no results) for every single read-only transaction without violating its serializability guarantee. The serial order that the system is equivalent to is simply a serial order where the read-only transactions happen before the first write transaction. In essence, the serializability guarantee allows transactions to “go back in time” --- as long as the final result is equivalent to some serial order, the guarantee is upheld. Without some kind of consistency guarantee, there are no restrictions on which serial order it needs to be equivalent to.
In general, all of the time travel bugs that I discussed in
a previous post in the context of serializability are possible at any isolation level.
Isolation levels only specify what happens for concurrent transactions. If two transactions are not running at the same time, no isolation guarantee in the world will specify how they should be processed. They are already perfectly isolated from each other by virtue of not running concurrently with each other! This is what makes time travel correctness bugs possible at even the highest levels of isolation. If you want guarantees for nonconcurrent transactions: for example, you want to be sure that a later transaction reads the writes of an earlier transaction,
you need consistency guarantees.
Many, but not all, consistency levels make real-time guarantees for nonconcurrent operations. For example, strict consistency and linearizable/atomic consistency both ensure that all nonconcurrent operations are ordered by real-time. Even lower consistency levels, such as sequential consistency and causal consistency make real time guarantees of operations within the same thread of execution.
So the bottom line is the following: once you have transactions with more than one operation, you need isolation guarantees. And if you need any kind of guarantee for non-concurrent transactions, you need consistency guarantees. Most of the time, if you are using a database system, you need both.
Therefore, as a database user, you need to figure out what you need in terms of isolation guarantees, and you also need to figure out what you need in terms of consistency guarantees. And if that wasn’t hard enough, you then need to figure out how to map what you think you need to the various options that your system gives you. This is where it gets really tricky, because many systems don’t view isolation and consistency as separate guarantees that can be intermixed arbitrarily. Rather, they only allow certain combinations of isolation guarantees and consistency guarantees, and give each combination a name. To make matters worse, the common industry practice is to call each name for a potential combination an “isolation level”, even though it is really a combination of an isolation level and a consistency level. We will give some examples in the next section.
“Isolation levels” that are really a mix of isolation and consistency guarantees
For my loyal readers that read everything I write, you might have been confused by my two posts on isolation guarantees when read together as a unit. In the
earlier of these two posts, I claimed that serializability is the highest possible isolation level. Then, in the
next post, I described a whole bunch of isolation levels there were seemingly “higher” or “more correct” --- “one-copy serializability”, “strong session serializability”, “strong write serializability”, “strong partition serializability”, and “strict serializability”.
But now that we have gotten to this point in this post --- if you have understood what I’ve written so far, hopefully now the answer to why this is not a contradiction is obvious. Serializability is indeed the highest possible isolation level. All variations of serializability that we discussed --- one-copy serializability, strong session serializability, strong write serializability, strong partition serializability, and strict serializability have identical isolation guarantees: they all guarantee serializability.
The only difference between these so called isolation levels are their consistency guarantees.
One-copy serializability guarantees sequential consistency where no thread of execution can process more than one transaction. Strong session serializability guarantees sequential consistency where each session corresponds to a separate thread of execution. Strong write serializability corresponds to a linearizability guarantee for write transactions, but only sequential consistency for read-only transactions. Strong partition serializability guarantees linearizable consistency within a partition, but only sequential consistency across partitions. And strict serializability guarantees linearizable consistency at all times for all reads and writes (across non-concurrent transactions).
The same method can be used to understand other so-called “isolation levels”. For example, the isolation levels of WEAK SNAPSHOT ISOLATION, STRONG SNAPSHOT ISOLATION, and STRONG SESSION SNAPSHOT ISOLATION are overviewed
in this paper. All of these “isolation levels” make equivalent isolation guarantees: all guarantee snapshot isolation and are thus susceptible to write skew anomalies. The only difference is that STRONG SNAPSHOT ISOLATION guarantees linearizable consistency (if timestamps are based on real time) alongside SNAPSHOT ISOLATION’s imperfect isolation guarantee, while the other levels pair lower levels of consistency with snapshot isolation.
Conclusion
Database system vendors will continue to use single terms to describe a particular mixture of isolation levels and consistency levels. My recommendation is to avoid getting confused by these loaded definitions and break them apart before starting to reason about them. If you see an “isolation level” with three or more words, chances are, it is really an isolation level combined with a consistency level. Break apart the term into the component isolation and consistency guarantees, and then carefully consider each guarantee separately. What does your application require as far as isolation of concurrently running transactions? Does the isolation guarantee that the isolation level is giving you match your requirements? Furthermore, what does your application require as far as ordering of non-concurrent transactions? Does the consistency guarantee that you extracted from the complex term match your requirements?
As a separate point, it is worth measuring the difference in performance you get between high isolation and consistency levels and lower ones. The quality of the architecture of the system can have a significant effect on the amount of performance drop for high isolation and consistency levels. Poorly designed systems will push you into choosing lower isolation and consistency levels by virtue of a dramatic performance drop if you choose higher levels. All systems will have some performance drop, but well-designed systems will observe a much less dramatic drop.