A quick caveat before we begin: Many of the comments on the HackerNews thread revolved around a back-and-forth between fans and contributors to the Apache Arrow project who went ballistic when they read my title with a sarcastic tone (the title was: “Apache Arrow vs. Parquet and ORC: Do we really need a third Apache project for columnar data representation?”) and more thoughtful and thorough readers who tried to calm them down and explain that the entire post was there to explain precisely why it makes sense to have Arrow as a separate project. However, one common point that was brought up by the pro-Arrow crowd was that my post was narrow in the sense that I only looked at Arrow from the perspective of using it as a storage format in the context of database and data analytics engines, whereas Arrow, as a general standard for representing data in main memory could also be used outside of this space. I should have been clearer about the scope of my analysis in that post, so this time around I want to be more clear: the scope of my analysis in this post is solely from the perspective of using Apache Arrow as a storage format in the context of database and data analytics engines and tools. I limit the scope to this context for two reasons: (1) I predict that the majority of Arrow’s use cases will be in that context (where I define data analytics tools broadly enough to include projects like Pandas) (2) As someone who has spent his entire career as a database system researcher, this is the only context in which I am qualified to present my opinion.
What exactly is Apache Arrow?
Arrow’s homepage self-describes in the following way: “Apache Arrow is a cross-language development platform for in-memory data. It specifies a standardized language-independent columnar memory format for flat and hierarchical data, organized for efficient analytic operations on modern hardware. It also provides computational libraries and zero-copy streaming messaging and interprocess communication.”In other words, the creators of Arrow envision the project having impact in three ways: (1) as a development platform, (2) as a columnar memory format standard, and (3) as a set of useful libraries.
In practice, the majority of the code in the Github repository at the time of my interactions with the codebase was for constructing, accessing, and testing data structures using the Arrow standard. So my analysis in this article will just focus on the Arrow standard and the set of code that is provided to help in the implementation of this standard.
Is it even possible to have everybody agree on a data representation standard?
For decades, it was impossible to fathom that there could be a standard representation for data in a database system. Database systems have historically been horribly monolithic and complex pieces of software. The many components of the system --- the storage layer, the transaction manager, the access manager, the recovery manager, the optimizer, etc. --- were significantly intertwined, and designed assuming particular architectural choices for the other components. Therefore, a “page” of data on storage was not a simple block of data, but also contained information critical to the recovery manager (e.g. the identifier of the log record that most recently wrote to this page), the transaction manager (e.g. timestamps required by multi-version concurrency control schemes), access manager, and so on. Each unique database system had different concurrency control schemes, different logging structures, and different index implementations; therefore a page of data in one system looked vastly different than a page of data in other system.Therefore, if you wanted to move data from one system to another one, you would have to “export” the data, which involved rewriting the data from the complex page format stored inside the system to a simpler representation of the data. This simple representation would be passed to the other system which would then rewrite the simple representation into its own proprietary standard. This process of rewriting the data before export is called “serialization” and rewriting it back before import is called “deserialization”. Serialization and deserialization costs when transferring data between systems have historically been necessary and unavoidable.
Over the past few decades, the database system world has changed significantly. First, people stopped believing that one size fits all for database systems, and different systems started being used for different workloads. Most notably, systems that specialized in data analysis separated from systems that specialized in transactional processing. Systems that specialized in data analysis tend to either be read-only or read-mostly systems, and therefore generally have far simpler concurrency control and recovery logic. Second, as the price of memory has rapidly declined, a larger percentage of database applications fit entirely in main memory. This also resulted in simpler recovery and buffer manager logic, which further simplified data representation. Finally, as open source database systems started to proliferate, a greater emphasis was placed on modular design and clean interfaces between the components of the system, in order to accommodate the typical distributed development of open source projects.
All of this has lead to much simpler data representations in main memory and analytical database engines, especially those in the open source sphere. Fixed width data types are often just represented in arrays, and variable-width data types in only slightly more complicated data structures. All of a sudden, the prospect of standardizing the data representation across main memory analytical database systems has become a realistic goal, thereby enabling the transfer of data between systems without having to pay serialization and deserialization costs.
This is exactly the goal of Apache Arrow. Arrow is, in its essence, a data representation specification --- a standard that can be implemented by any engine that processes data in main memory. Engines that use this standard internally can avoid any kind of serialization and deserialization costs when moving data between each other, which several other blog posts (e.g. here and here) have shown to result in significant performance gains. 13 major open source projects, including Pandas, Spark, Hadoop and Dremio have already embraced the standard, which I believe is enough critical mass for the Arrow standard to become ubiquitous in the data analytics industry. Even if existing systems do not adopt the standard for their own internal data representation, I expect they will at least support data exports in Arrow. This increases the motivation for any new main memory analytics engine being designed to adopt it.
While ubiquity is usually a good indicator of quality, there are plenty of languages, APIs, and pieces of software that become ubiquitous for reasons entirely unrelated to their quality. For example, the SQL interface to database systems took off due to the business dominance of the systems that used SQL, even though there were arguably better interfaces to database systems that had been proposed prior to SQL’s take-over. Furthermore, even high quality things are often optimized for certain scenarios, and yield suboptimal performance in scenarios outside of the intended sweet spot. Therefore, I took a deeper look at Apache Arrow without any preconceived biases. Below, I present my analysis and experience with playing with the code of the project, and discuss some of the design decisions of Arrow, and the tradeoffs associated with those decisions.
Columnar
It would be easy for someone who sees Arrow’s self-description of being “columnar” to mistakenly assume that Arrow’s scope is limited to two dimensional data structures that have rows and columns, and that by being “columnar”, it is possible to derive that Arrow stores data column-by-column instead of row-by-row. In fact, Arrow is actually a more general standard --- including specification for one-dimensional data structures such as arrays and lists, and also data structures with more than two dimensions through its support for nesting. Nonetheless, we have all become accustomed to interacting with data through relational database systems and spreadsheets, both of which store data in two dimensional objects, where each row corresponds to an entity, and each column an attribute about that entity. By being columnar, Apache Arrow stores such two dimensional objects attribute by attribute instead of entity by entity. In other words, the first attribute of each entity is stored contiguously, then the second attribute of every entity, and so on.This columnar representation means that if you want to extract all attributes for a particular entity, the system must jump around memory, finding the data for that entity from each of the separately-stored attributes. This results in a random memory access pattern which results in slower access times than sequential access patterns (my previous post discusses this point in more detail). Therefore, Arrow is not ideal for workloads that tend to read and write a small number of entire entities at once, such as OLTP (transactional) workloads. On the other hand, data analytics workloads tend to focus on only a subset of the attributes at once; scanning through large quantities of entities to aggregate values of these attributes. Therefore, storing data in a columnar fashion results in sequential, high performance access patterns for these workloads.
Storing data column-by-column instead of row-by-row has other advantages for analytical workloads as well --- for example it enables SIMD acceleration and potentially increases compression rates (my previous post goes into more detail on these subjects). The bottom line is that by choosing a columnar representation for two-dimensional data structures, Arrow is clearly positioning itself for adoption by data analytics workloads that do not access individual data items, but rather access a subset of the attributes (columns) from many data items. Indeed, many of the open source projects that have been built natively on Arrow, such as Dremio and NVIDIA’s Open GPU Accelerated Analytics (GOAI), are focused on analytics.
Fixed-width data types
Note that attributes of entities tend to have a uniform data type. Therefore, by choosing a columnar data representation, Arrow can store columns of two dimensional tables in an identical way to how it stores data in one dimension of uniform type. In particular, fixed-width data types such as integers and floats can simply be stored in arrays. Arrow is little endian by default and pads arrays to 64-byte boundaries. Aside from the extra padding, Arrow arrays store data in memory in an equivalent fashion to arrays in C, except that Arrow arrays have three extra pieces of metadata that are not present in C arrays: (1) the length of the array, (2) the number of null elements in the array, and (3) a bitmap indicating which elements of the array are null. One interesting design decision made by Arrow is that null elements of the array take up an identical amount of space as non-null elements --- the only way to know if an element is null is by checking to see if there is a 1-bit in the associated bit for that element in null-bitmap that is part of the metadata for the array. The alternative design would have been to not waste storage at all on the null elements, and instead derive the location of null elements by inspection of the null bitmap. The tradeoff here is storage space vs random access performance. By expending space on null elements, the nth element of the array can be quickly located by simply multiplying n by the fixed-width size of each element in the array. However, if the null elements are removed from the array (and their location derived from the null bitmap), the amount of space needed to store the array will be smaller, but additional calculations and bit counting must occur before finding the value for an element in the array at a particular index. On the other hand, sequential scans of the entire array may be faster if the system is bottlenecked by memory bandwidth, since the array is smaller.Since Arrow’s design decision was made to optimize for random array element access, I ran a simple benchmark where I created an array of size 100,000,000 32-bit integers, put random values in each element of the array, and then searched for the value at 50,000 different locations in the array. I first tried this experiment in a regular C array that allowed null elements to take up an identical amount of space as non-null elements (similar to Arrow). I then tried a different C array where nulls take up no space, and a high performance index is used to speed up random access of the array . I then installed Apache Arrow, built the same array using the Int32Builder in the Arrow C++ API and accessed it through the Arrow Int32Array API. I ran these experiments on an EC2 t2.medium instance. The results are shown below:
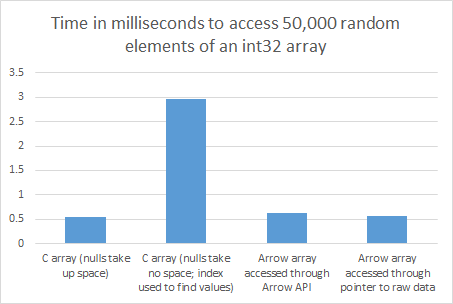
As expected, the version of the C array where nulls take up no space was much slower than the other options for this random access workload. Even though we used a high performance index, direct address offset calculations are always faster. Accessing data through the API that comes with the Arrow codebase was slightly slower than accessing data from an array directly. However, this is not because of the Arrow data format itself. When, after building the Arrow Array, instead of accessing the array through the Arrow API, I instead accessed a pointer to the raw data in the array, cast it as a const int*, and then proceeded to access this raw data directly in C, I saw equivalent performance to a normal C array. This cause of the slowdown from accessing data through the Arrow API is presumably from the C++ compiler failing to inline all of the extra function calls (despite the -O3 flag). I therefore conclude that for applications the are extremely performance sensitive, it is better to access raw data created in accordance to the Arrow specification than to use the API to access the data. But for most cases, using the API will be sufficient. As far as the decision to allow nulls to take up space, that was certainly a win for this random-access workload. But for a workload that scans through the entire dataset, it would have been up to 10% faster for the C array in which nulls take up no space, since in our experiment, 10% of all the values were null, and thus that version of the C array was 10% smaller than for the Arrow-specified arrays.
Variable-width data types
For variable width data types, Arrow stores the data for each element contiguously in memory without any separator bytes between the elements. In order to determine where one element ends and the next one begins, Arrow stores the byte offset of the first byte of each element of the array inside an integer array next to the raw data (there is an example in the next section below). In order to access a random element of the variable-width array, the integer array is accessed to find out the starting position of this and the next element in the raw data (the difference between these positions is the length of the element), and then the raw data is accessed.The decision not to include separator bytes in the raw data between the elements makes the solution more general --- you don’t have to reserve special byte values for these separators. However, it slows down certain types of sequential access patterns. For example, I ran an experiment where I created an array of 12,500,000 variable-sized strings (average of 8 characters per string) using the StringBuilder API, and searched for a substring of size two characters within all elements of the array (extracting the index of all elements that contain the substring). I measured how long this query took when accessing the array both through the Arrow StringArray C++ API, and also over the raw Arrow data directly. Thirdly, I measured how long the same query took over a string array that included a separator byte between each element. The results are shown below:

In this case, the best performance was the array that was not created according to the Arrow specification. The reason for this is that the raw data could not be searched directly for the two-byte substring in the dataset created according to the Arrow specification, because the companion integer array containing the list of element boundaries needed to be repeatedly consulted to ensure that substring matches did not span multiple elements. However, when seperator bytes were located inside the array itself, no secondary array needed to be scanned.
It should be noted that string separators only accelerate certain types of queries, and I purposely chose one such query for this example. For queries that they do not accelerate, they tend to have to opposite effect, decreasing performance by bloating the size of the array. Furthermore, it should be reiterated at this point that reserving byte values for string separators would have prevented any application that do not reserve the same byte values from using Arrow, thereby limiting the scope of Arrow’s utility. In addition, many other queries can actually benefit from having the companion integer array. For example, an equality comparison (name == "johndoe") can utilize the integer array to ignore any value that has a different length. It should also be noted that any application that wishes to have string separators can simply add them to their strings directly, before creating the array using the StringBuilder API. So this experiment does not show a fundamental weakness of the Arrow standard --- it just indicates that in some cases you may have to add to the raw data in order to get optimal performance.
Nested Data
As self-describing data formats such as JSON become more popular, users are increasingly dropping the two-dimensional restrictions of relational tables and spreadsheets, and instead using nested models for their data. Arrow elegantly deals with nested data without requiring conceptual additions to the basic layout principles described above, where raw data is stored contiguously and offset arrays are used to quickly find particular data elements. For example, in a data set describing classes at the University of Maryland, I may want to nest the list of students in each class. For example, the data set:Classes:
Name: Introduction to Database Systems
Instructor: Daniel Abadi
Students: Alice
Bob
Charlie
Name: Advanced Topics in Database Systems
Instructor: Daniel Abadi
Students: Andrew
Beatrice
could be stored as follows:
Name offsets: 0, 32, 67
Name values: Introduction to Database SystemsAdvanced Topics in Database Systems
Instructor offsets: 0, 12, 24
Instructor values: Daniel AbadiDaniel Abadi
Nested student list offsets: 0, 3, 5
Student offsets: 0, 5, 8, 15, 21, 29
Student values: AliceBobCharlieAndrewBeatrice
Note that the nested student attribute required two different offset lists: (1) Students are variable length and thus we need one offset list to specify where one student ends and the next one begins, just as for any variable length attribute; and (2) We need second offset list to indicate how many students exist per class. The "Nested student list offsets" accomplish this second goal --- it indicates that the first class has (3-0) students, and the second class has (5-3) students, etc.
Arrow currently allows list, struct, and various types of union type data to be nested in an attribute value.