The two-phase commit protocol (2PC) has been used in enterprise software systems for over three decades. It has been an an incredibly impactful protocol for ensuring atomicity and durability of transactions that access data in multiple partitions or shards. It is used everywhere --- both in older “venerable” distributed systems, database systems, and file systems such as Oracle, IBM DB2, PostgreSQL, and Microsoft TxF (transactional NTFS), and in younger “millennial” systems such as MariaDB, TokuDB, VoltDB, Cloud Spanner, Apache Flink, Apache Kafka, and Azure SQL Database. If your system supports ACID transactions across shards/partitions/databases, there’s a high probability that it is running 2PC (or some variant thereof) under the covers. [Sometimes it’s even “over the covers” --- older versions of MongoDB required users to implement 2PC for multi-document transactions in application code.]
In this post, we will first describe 2PC: how it works and what problems it solves. Then, we will show some major issues with 2PC and how modern systems attempt to get around these issues. Unfortunately, these attempted solutions cause other problems to emerge. In the end, I will make the case that the next generation of distributed systems should avoid 2PC, and how this is possible.
Overview of the 2PC protocol
There are many variants of 2PC, but the basic protocol works as follows:
Background assumption:The work entailed by a transaction has already been divided across all of the shards/partitions that store data accessed by that transaction. We will refer to the effort performed at each shard as being performed by the “worker” for that shard. Each worker is able to start working on its responsibilities for a given transaction independently of each other. The 2PC protocol begins at the end of transaction processing, when the transaction is ready to “commit”. It is initiated by a single, coordinator machine (which may be one of the workers involved in that transaction).
The basic flow of the 2PC protocol is shown in the figure below. [The protocol begins at the top of the figure and then proceeds in a downward direction.]
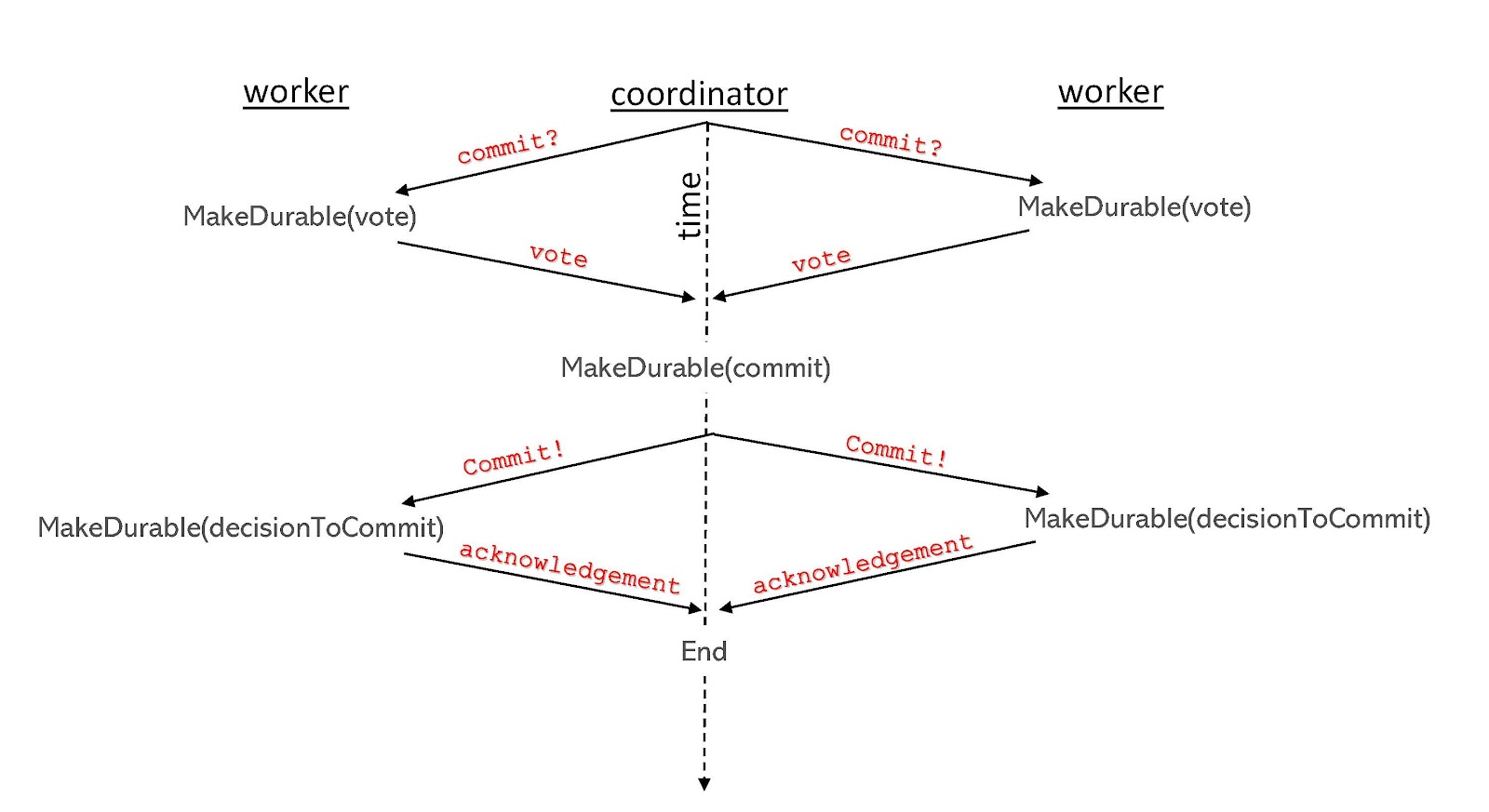
Phase 1: A coordinator asks each worker whether they have successfully completed their responsibilities for that transaction and are ready to commit. Each worker responds ‘yes’ or ‘no’.
Phase 2: The coordinator counts all the responses. If every worker responded ‘yes’, then the transaction will commit. Otherwise, it will abort. The coordinator sends a message to each worker with the final commit decision and receives an acknowledgement back.
This mechanism ensures the atomicity property of transactions: either the entire transaction will be reflected in the final state of the system, or none of it. If even just a single worker cannot commit, then the entire transaction will be aborted. In other words: each worker has “veto-power” for a transaction.
It also ensures transaction durability. Each worker ensures that all of the writes of a transaction have been durably written to storage prior to responding ‘yes’ in phase 1. This gives the coordinator freedom to make a final decision about a transaction without concern for the fact that a worker may fail after voting ‘yes’. [In this post, we are being purposefully vague when using the term “durable writes” --- this term can either refer to writing to local non-volatile storage or, alternatively, replicating the writes to enough locations for it to be considered “durable”.]
In addition to durably writing the writes that are directly required by the transaction, the protocol itself requires additional writes that must be made durable before it can proceed. For example, a worker has veto power until the point it votes ‘yes’ in phase 1. After that point, it cannot change its vote. But what if it crashes right after voting ‘yes’? When it recovers it might not know that it voted ‘yes’, and still think it has veto power and go ahead and abort the transaction. To prevent this, it must write its vote durably before sending the ‘yes’ vote back to the coordinator. [In addition to this example, in standard 2PC, there are two other writes that are made durable prior to sending messages that are part of the protocol.]
The problems with 2PC
There are two major problems with 2PC. The first is well known, and discussed in every reputable textbook that presents 2PC. The second is much less well known, but a major problem nonetheless.
The well-known problem is referred to as the “blocking problem”. This happens when every worker has voted ‘yes’, but the coordinator fails before sending a message with the final decision to at least one worker. The reason why this is a problem is that by voting ‘yes’, each worker has removed its power to veto the transaction. However, the coordinator still has absolute power to decide the final state of a transaction. If the coordinator fails before sending a message with the final decision to at least one worker, the workers cannot get together to make a decision amongst themselves --- they can’t abort because maybe the coordinator decided to commit before it failed, and they can’t commit because maybe the coordinator decided to abort before it failed. Thus, they have to block --- wait until the coordinator recovers --- in order to find out the final decision. In the meantime, they cannot process transactions that conflict with the stalled transaction since the final outcome of the writes of that transaction are yet to be determined.
There are two categories of work-arounds to the blocking problem. The first category of work-around modifies the core protocol in order to eliminate the blocking problem. Unfortunately, these modifications reduce the performance --- typically by adding an extra round of communication --- and thus are rarely used in practice. The second category keeps the protocol in tact but reduces the probability of the types of coordinator failure than can lead to the blocking program --- for example, by running 2PC over replica consensus protocols and ensuring that important state for the protocol is replicated at all times. Unfortunately, once again, these work-arounds reduce performance, since the protocol requires that these replica consensus rounds occur sequentially, and thus they may add significant latency to the protocol.
The lesser-known problem is what I call the “cloggage problem”. 2PC occurs after transaction is processed, and thus necessarily increases the latency of the transaction by an amount equal to the time it takes to run the protocol. This latency increase alone can already be an issue for many applications, but a potentially larger issue is that worker nodes do not know the final outcome of a transaction until mid-way through the second phase. Until they know the final outcome, they have to be prepared for the possibility that it might abort, and thus they typically prevent conflicting transactions from making progress until they are certain that the transaction will commit. These blocked transactions in turn block other transactions from running, and so on, until 2PC completes and all of the blocked transactions can resume. This cloggage further increases the average transaction latency and also decreases transactional throughput.
To summarize the problems we discussed above: 2PC poisons a system along four dimensions: latency (the time of the protocol plus the stall time of conflicting transactions), throughput (because it prevents conflicting transactions from running during the protocol), scalability (the larger the system, the more likely transactions become multi-partition and have to pay the throughput and latency costs of 2PC), and availability (the blocking problem we discussed above). Nobody likes 2PC, but for decades, people have assumed that it is a necessary evil.
It’s time to move on
For over three decades, we’ve been stuck with two-phase commit in sharded systems. People are aware of the performance, scalability, and availability problems it introduces, but nonetheless continue on, with no obvious better alternative.
The truth is, if we would just architect our systems differently, the need for 2PC would vanish. There have been some attempts to accomplish this --- both in academia (such as this SIGMOD 2016 paper) and industry. However, these attempts typically work by avoiding multi-sharded transactions in the first place, such as by repartitioning data in advance of a transaction so that it is no longer multi-sharded. Unfortunately, this repartitioning reduces performance of the system in other ways.
What I am calling for is a deeper type of change in the way we architect distributed systems. I insist that systems should still be able to process multi-sharded transactions --- with all the ACID guarantees and what that entails --- such as atomicity and durability --- but with much simpler and faster commit protocols.
It all comes down to a fundamental assumption that has been present in our systems for decades: a transaction may abort at any time and for any reason. Even if I run the same transaction on the same initial system state … if I run it at 2:00PM it may commit, but at 3:00 it may abort.
There are several reasons why most architects believe we need this assumption. First, a machine may fail at anytime --- including in the middle of a transaction. Upon recovery, it is generally impossible to recreate all of the state of that transaction that was in volatile memory prior to the failure. As a result, it is seemingly impossible to pick up where the transaction left off prior to the failure. Therefore, the system aborts all transactions that were in progress at the time of the failure. Since a failure can occur at any time, this means that a transaction may abort at any time.
Second, most concurrency control protocols require the ability to abort a transaction at any time. Optimistic protocols perform a “validation” phase after processing a transaction. If validation fails, the transaction aborts. Pessimistic protocols typically use locks to prevent concurrency anomalies. This use of locks may lead to deadlock, which is resolved by aborting (at least) one of the deadlocked transactions. Since deadlock may be discovered at any time, the transaction needs to retain the ability to abort at any time.
If you look carefully at the two-phase commit protocol, you will see that this arbitrary potential to abort a transaction is the primary source of complexity and latency in the protocol. Workers cannot easily tell each other whether they will commit or not, because they might still fail after this point (before the transaction is committed) and want to abort this transaction during recovery. Therefore, they have to wait until the end of transaction processing (when all important state is made durable) and proceed in the necessary two phases: in the first phase, each worker publically relinquishes its control to abort a transaction, and only then can the second phase occur in which a final decision is made and disseminated.
In my opinion we need to remove veto power from workers and architect systems in which the system does not have freedom to abort a transaction whenever it wants during its execution. Only logic within a transaction should be allowed to cause a transaction to abort. If it is theoretically possible to commit a transaction given an current state of the database, that transaction must commit, no matter what types of failures occur. Furthermore, there must not be race conditions relative to other concurrently running transactions that can affect the final commit/abort state of a transaction.
Removing abort flexibility sounds hard. We’ll discuss soon how to accomplish this. But first let’s observe how the commit protocol changes if transactions don’t have abort flexibility.
What a commit protocol looks like when transactions can’t abort arbitrarily
Let’s look at two examples:
In the first example, assume that the worker for the shard that stores the value for variable X is assigned a single task for a transaction: change the value of X to 42. Assume (for now) that there are no integrity constraints or triggers defined on X (which may prevent the system from setting X to 42). In such a case, that worker is never given the power to be able to abort the transaction. No matter what happens, that worker must change X to 42. If that worker fails, it must change X to 42 after it recovers. Since it never has any power to abort, there is no need to check with that worker during the commit protocol to see if it will commit.
In the second example, assume that the worker for the shard that stores the value for variables Y and Z is assigned two tasks for a transaction: subtract 1 from the previous value of Y and set Z to the new value of Y. Furthermore, assume that there is an integrity constraint on Y that states that Y can never go below 0 (e.g., if it represents the inventory of an item in a retail application). Therefore, this worker has to run the equivalent of the following code:
IF (Y > 0)
Subtract 1 from Y
ELSE
ABORT the transaction
Z = Y
This worker must be given the power to abort the transaction since this required by the logic of the application. However, this power is limited. Only if the initial value of Y was 0 can this worker abort the transaction. Otherwise, it has no choice but to commit. Therefore, it doesn’t have to wait until it has completed the transaction code before knowing whether it will commit or not. On the contrary: as soon as it has finished executing the first line of code in the transaction, it already knows its final commit/abort decision. This implies that the commit protocol will be able to start much earlier relative to 2PC.
Let’s now combine these two examples into a single example in which a transaction is being performed by two workers --- one of them is doing the work described in the first example, and the other one doing the work described in the second example. Since we are guaranteeing atomicity, the first worker cannot simply blindly set X to 42. Rather, it’s own work must also be dependent on the value of Y. In effect, it’s transaction code becomes:
temp = Do_Remote_Read(Y)
if (temp > 0)
X = 42
Note that if the first worker’s code is written in this way, the code for the other worker can be simplified to just:
IF (Y > 0)
Subtract 1 from Y
Z = Y
By writing the transaction code in this way, we have removed explicit abort logic from both workers. Instead, both workers have if statements that check for the constraint that would have caused the original transaction to abort. If the original transaction would have aborted, both workers end up doing nothing. Otherwise, both workers change the values of their local state as required by the transaction logic.
The important thing to note at this point is that the need for a commit protocol has been totally eliminated in the above code. The system is not allowed to abort a transaction for any reason other than conditional logic defined by application code on a given state of the data. And all workers condition their writes on this same conditional logic so that they can all independently decide to “do nothing” in those situations where a transaction cannot complete as a result of current system state. Thus, all possibility of a transaction abort has been removed, and there is no need for any kind of distributed protocol at the end of transaction processing to make a combined final decision about the transaction. All of the problems of 2PC have been eliminated. There is no blocking problem because there is no coordinator. And there is no cloggage problem, because all necessary checks are overlapped with transaction processing instead of after it completes.
Moreover, as long as the system is not allowed to abort a transaction for any reason other than the conditional application logic based on input data state, it is always possible to rewrite any transaction as we did above in order to replace abort logic in the code with if statements that conditionally check the abort conditions. Furthermore, it is possible to accomplish this without actually rewriting application code. [The details of how to do this are out of scope for this post, but to summarize at a high level: shards can set special system-owned boolean flags when they have completed any conditional logic that could cause an abort, and it is these boolean flags that are remotely read from other shards.]
In essence: there are two types of aborts that are possible in transaction processing systems: (1) Those that are caused by the state of the data and (2) Those that are caused by the system itself (e.g. failures or deadlocks). Category (1) can always be written in terms of conditional logic on the data as we did above. So if you can eliminate category (2) aborts, the commit protocol can be eliminated.
So now, all we have to do is explain how to eliminate category (2) aborts.
Removing system-induced aborts
I have spent almost an entire decade designing systems that do not allow system-induced aborts. Examples of such systems are Calvin, CalvinFS, Orthrus, PVW, and a system that processes transactions lazily. The impetus for this feature came from the first of these projects --- Calvin --- because of its status of being a deterministic database system. A deterministic database guarantees that there is only one possible final state of the data in the database given a defined set of input requests. It is therefore possible to send the same input to two distinct replicas of the system and be certain that the replicas will process this input independently and end up in the same final state, without any possibility of divergence.
System-induced aborts such as system failure or concurrency control race conditions are fundamentally nondeterministic events. It is very possible that one replica will fail or enter a race condition while the other replica will not. If these nondeterministic events were allowed to result in an a transaction to abort, then one replica may abort a transaction while the other one would commit --- a fundamental violation of the deterministic guarantee. Therefore, we had to design Calvin in a way that failures and race conditions cannot result in a transaction to abort. For concurrency control, Calvin used pessimistic locking with a deadlock avoidance technique that ensured that the system would never get into a situation where it had to abort a transaction due to deadlock. In the face of a system failure, Calvin did not pick up a transaction exactly where it left off (because of the loss of volatile memory during the failure). Nonetheless, it was able to bring the processing of that transaction to completion without having to abort it. It accomplished this via restarting the transaction from the same original input.
Neither of these solutions --- neither deadlock avoidance nor transaction restart upon a failure --- are limited to being used in deterministic database systems. [Transaction restart gets a little tricky in nondeterministic systems if some of the volatile state associated with a transaction that was lost during a failure was observed by other machines that did not fail. But there are simple ways to solve this problem that are out of scope for this post.] Indeed, some of the other systems I linked to above are nondeterministic systems. Once we realized the power that comes with removing system-level aborts, we built this feature into every system we built after the Calvin project --- even the nondeterministic systems.
Conclusion
I see very little benefit in system architects making continued use of 2PC in sharded systems moving forward. I believe that removing system-induced aborts and rewriting state-induced aborts is the better way forward. Deterministic database systems such as Calvin or FaunaDB always remove system-induced aborts anyway, and thus usually can avoid 2PC as we described above. But it is a huge waste to limit this benefit to only deterministic databases. It is not hard to remove system-induced aborts from nondeterministic systems. Recent projects have shown that it is even possible to remove system-induced aborts in systems that use concurrency control techniques other than pessimistic concurrency control. For example, both the PVW and the lazy transaction processing systems we linked to above use a variant of multi-versioned concurrency control. And FaunaDB uses a variant of optimistic concurrency control.
In my opinion there is very little excuse to continue with antiquated assumptions regarding the need for system-induced aborts in the system. In the old days when systems ran on single machines, such assumptions were justifiable. However, in modern times, where many systems need to scale to multiple machines that can fail independently of each other, these assumptions require expensive coordination and commit protocols such as 2PC. The performance problems of 2PC has been a major force behind the rise of non-ACID compliant systems that give up important guarantees in order to achieve better scalability, availability, and performance. 2PC is just too slow --- it increases the latency of all transactions --- not just by the length of the protocol itself, but also by preventing transactions that access the same set of data from running concurrently. 2PC also limits scalability (by reducing concurrency) and availability (the blocking problem we discussed above). The way forward is clear: we need to reconsider antiquated assumptions when designing our systems and say “good-bye” to two phase commit!
[This article includes a description of work that was funded by the NSF under grant IIS-1763797. Any opinions, findings, and conclusions or recommendations expressed in this article are those of Daniel Abadi and do not necessarily reflect the views of the National Science Foundation.]