The Strict Serializability vs. Low Latency Tradeoff
Modern applications span geographic borders with users located on any continent worldwide. Application state thus must be accessible anywhere. If application state never changes, it is possible for all users to interact with the global application with low latency. Application state is simply replicated to many locations around the world, and users can interact with their nearest replica. But for most applications, state changes over time: products get purchased, money is exchanged, users become linked, resources are consumed, etc. The problem is: sending messages across the world can take hundreds of milliseconds. There is thus a necessary delay before information about the state change travels to all parts of the world. In the meantime, applications have two choices: they can present stale, out-of-date state to the user, or they make the user wait until the correct, up-to-date state arrives.Presenting stale state allows for low-latency interactions with the application around the world, but may lead to negative experiences by the end user. For example, observing stale state may result in users purchasing products that no longer exist, overdrawing balances from bank accounts, confusing discussion threading on social media, or reacting to incorrect stimuli in online multiplayer games.
Applications typically store state in some kind of “data store”. Some data stores guarantee “strong consistency” (such as strict consistency, atomic consistency, or linearizability, which I discussed in a previous post) that ensures that stale state will never be accessed. More specifically: any requests to access state on behalf of a client will reflect all state changes that occurred prior to that request. However, guaranteeing strong consistency may result in slower (high-latency) response times. In contrast, other data stores make reduced consistency guarantees and as a result, can achieve improved latency. In short, there is a tradeoff between consistency and latency: this is the ELC part of the PACELC theorem.
Separately, some systems provide support for transactions: groups of read and write requests that occur together as atomic units. Such systems typically provide “isolation” guarantees that prevent transactions from reading incomplete/temporary/incorrect data that were written by other concurrently running transactions. There are different levels of isolation guarantees, that I’ve discussed at length in previous posts (post 1, post 2, post 3), but the highest level is “serializability”, which guarantees that concurrent transactions are run in an equivalent fashion to how they would have been run if there were no other concurrently running transactions. In geo-distributed systems, where concurrently running transactions are running on physically separate machines that are potentially thousands of miles apart, serializability becomes harder to achieve. If fact, there exist proofs in the literature that show that there is a fundamental tradeoff between serializability and latency in geographically distributed systems.
Bottom line: there is a fundamental tradeoff between consistency and latency. And there is another fundamental tradeoff between serializability and latency.
Strict serializability includes perfect isolation (serializability) and consistency (linearizability) guarantees. If either one of those guarantees by itself is enough to incur a tradeoff with latency, then certainly the combination will necessarily require a latency tradeoff.
Indeed, a close examination of the commercial (and academic) data stores that guarantee strict serializability highlights this latency tradeoff. For example, Spanner (along with all the Spanner-derivative systems: Cloud Spanner, CockroachDB, and YugaByte) runs an agreement protocol (e.g. Paxos/Raft) as part every write to the data store in order to ensure that a majority of replicas agree to the write. This global coordination helps to ensure strict serializability, but increases the latency of each write. [Side note: neither CockroachDB nor YugaByte currently guarantee full strict serializability, but the reason for that is unrelated the discussion in this post, and discussed at length in several of my previous posts (post 1, post 2). The main point that is relevant for this post is that they inherit Spanner’s requirement to do an agreement protocol upon each write, which facilitates achieving a higher level of consistency than what would have been achieved if they did not inherit this functionality from Spanner.]
For example, if there are three copies of the data --- in North America, Europe, and Asia --- then every single write in Spanner and Spanner-derivative systems require agreement between at least two continents before it can complete. It is impossible to complete a write in less than 100 milliseconds in such deployments. Such high write latencies are unacceptable for most applications. Cloud Spanner, aware of this this latency problem that arises from the Spanner architecture, refuses to allow such “global” deployments. Rather, all writable copies of data must be within a 1000 mile radius (as of the time of publications of this post … see: https://cloud.google.com/spanner/docs/instances which currently says: “In general, the voting regions in a multi-region configuration are placed geographically close—less than a thousand miles apart—to form a low-latency quorum that enables fast writes (learn more).”). Spanner replicas outside of this 1000 mile radius must be read-only replicas that operate at a lag behind the quorum eligible copies. In summary, write latency is so poor in Spanner that they disable truly global deployments. [Side note: CockroachDB improves over Spanner by allowing truly global deployments and running Paxos only within geo-partitions, but as mentioned in the side note above, not with strict serializability.]
Amazon Aurora --- like Cloud Spanner --- explicitly disables strictly serializable global deployments. As of the time of this post, Aurora only guarantees serializable isolation for single-master deployments, and even then only on the primary instance. The read-only replicas operate at a maximum of “repeatable read” isolation.
Calvin and Calvin-derivative systems (such as Fauna, Streamy-db, and T-Part) typically have better write latency than Spanner-derivative systems (see my previous post on this subject for more details), but they still have to run an agreement protocol across the diameter of the deployment for every write transaction. The more geographically disperse the deployment, the longer the write latency.
In the research literature, papers like MDCC and TAPIR require at least one round trip across the geographic diameter of the deployment in order to guarantee strict serializability. Again: for truly global deployments, this leads to hundreds of milliseconds of latency.
In short: whether you focus on the theory, or whether you focus on the practice, it is seemingly impossible to achieve both strict serializability (for arbitrary transactions) and low latency reads and writes.
How SLOG cheats Strict Serializability vs. Low Latency Tradeoff
Let’s say that a particular data item was written by a client in China. Where is the most likely location from which it will be accessed next? In theory, it could be accessed from anywhere. But in practice for most applications, (at least) 8 times out of 10, it will be accessed by a client in China. There is a natural locality in data access that existing strictly serializable systems have failed to exploit.If the system can be certain that the next read after a write will occur from the same region of the world that originated the write, there is no need (from a strict serializability correctness perspective) to synchronously replicate the write to any other region. The next read will be served from the same near-by replica from which the write originated, and is guaranteed to see the most up to date value. The only reason to synchronously replicate to another region is for availability --- in case an entire region fails. Entire region failure is rare, but still important to handle in highly available systems. Some systems, such as Amazon Aurora, only synchronously replicate to a nearby region. This limits the latency effect from synchronous replication. Other systems, such as Spanner, run Paxos or Raft, which causes synchronous replication to a majority of regions in a deployment --- a much slower process. The main availability advantage of Paxos/Raft over replication to only nearby regions is to be able to remain (partially) available in the event of network partitions. However, Google themselves claim that network partitions are very rare, and have almost no effect on availability in practice. And Amazon clearly came to the same conclusion in their decision to avoid Paxos/Raft from the beginning.
To summarize, in practice: replication within a region and to near-by regions can achieve near identical levels of availability as Paxos/Raft, yet avoid the latency costs. And if there is locality in data access, there is no need to run synchronous replication of every write for any reason unrelated to availability. So in effect, for workloads with access locality, there is no strict serializability vs. low latency tradeoff. Simply serve reads from the same location as the most recent write to that same data item, and synchronously replicate writes only within a region and to near-by regions for availability.
Now, let’s drop the assumption of perfect locality. Those reads that initiate far from where that data item was last written must travel farther and thus necessarily take longer (i.e. high latency). If such reads are common, it is indeed impossible to achieve low latency and strict serializability at the same time. However, as long as the vast majority of reads initiate from locations near to where that item was last written, the vast majority of reads will achieve low latency. And writes also achieve low latency (since they are not synchronously replicated across the geographic diameter of the deployment). In short, low latency is achieved for the vast majority of reads and writes, without giving up strict serializability.
Where things get complicated are (1) How does the system which is processing a read know which region to send it to? In other words, how does any arbitrary region know which was the last region to write a data item? (2) What happens if a transaction needs to access multiple data items that were last written by different regions?
The solution to (1) is simpler than the solution to (2). For (1), each data item is assigned only one region at a time as its “home region”. Write to that data item can only occur at that home region. As the region locality of a data item shifts over time, an explicit hand-off process automatically occurs in which that data item is “rehoused” at a new region. Each region has a cache of the current house for each data item. If the cache is out of date for a particular read, the read will be initially sent to the wrong region, but that region will immediately forward the read request to the new home of that data item.
The solution to (2) is far more complicated. Getting such transactions to run correctly without unreasonably high latencies was a huge challenge. Our initial approach (not discussed in the paper we published) was to rehouse all data items accessed by a transaction to the same region prior to running it. Unfortunately, this approach interfered with the system’s ability to take advantage of the natural region locality in a workload (by forcing data items to be rehoused to non-natural locations) and made it nearly impossible to run transactions with overlapping access sets in parallel, which destroyed the throughput scalability of the system.
Instead, the paper we published uses a novel asynchronous replication algorithm that is designed to work with a deterministic execution framework based on our previous research on Calvin. This solution enables processing of “multi-home” transactions with no forced-rehousing, with half-round-trip cross-region latency. For example, let’s say that a transaction wants to read, modify, and write two data items: X and Y, where X is housed in the USA and Y is housed in Europe. All writes to X that occurred prior to this transaction are asynchronously sent from the USA to Europe, and (simultaneously) all writes to Y that occurred prior to this transaction are asynchronously sent from Europe to the USA. After this simple one-way communication across the contents is complete, each region then independently runs the read/modify/writes to both X and Y locally, and rely on determinism to ensure that they both are guaranteed to write the same exact values and come to the same commit/abort decision for the transaction without further communication.
Obviously there are many details that I’m leaving out of this short blog post. The reader is encouraged to look at the full paper for more details. But the final performance numbers are astonishingly good. SLOG is able to get the same throughput as state-of-the-art geographically replicated systems such as Calvin (which is an order of magnitude better than Spanner) while at the same time getting an order of magnitude better latency for most transactions, and equivalent latency to Paxos-based systems such as Calvin and Spanner for the remaining “multi-home” transactions.
An example of the latency improvement of SLOG over Paxos/Raft-based systems for a workload in which 90% of all reads initiate from the same region as where they were last written is shown in the figure below: [Experimental setup is described in the paper, and is run over a multi-continental geo-distributed deployment that includes locations on the west and east coasts of the US, and Europe.]
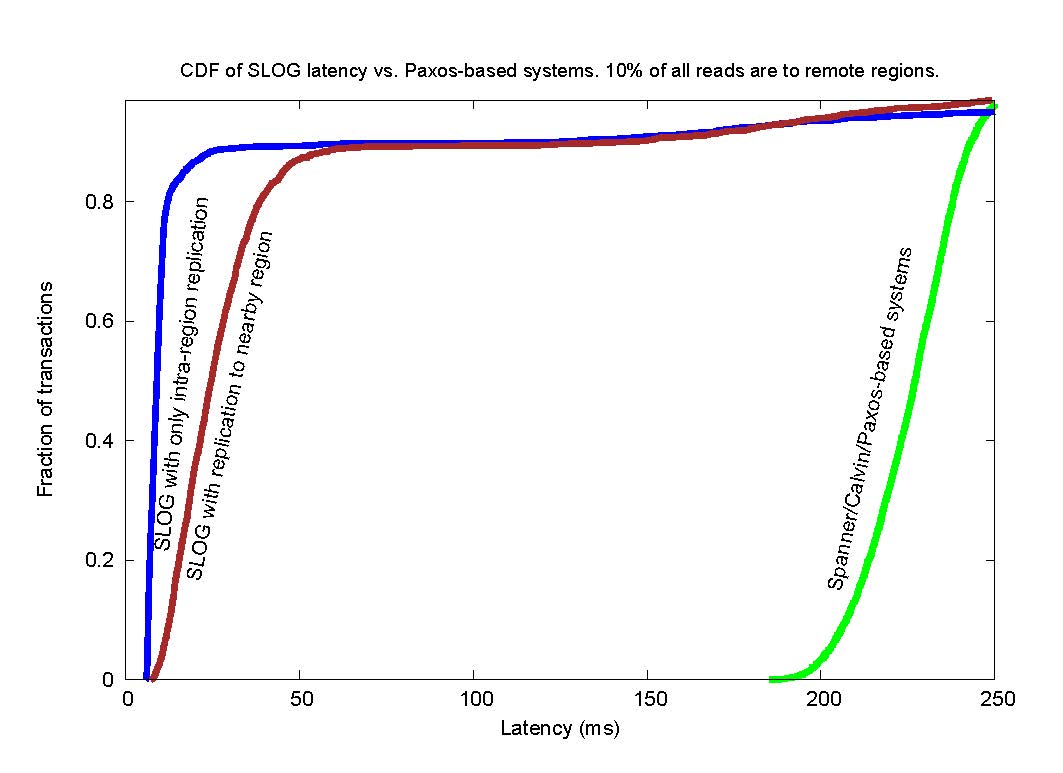
This figure shows two versions of SLOG --- one version that only replicates data within the same region, and one version that replicates also to a near-by region (to be robust to entire region failure). For the version of SLOG with only intra-region replication, the figure shows that 80% of transactions complete in less than 10 milliseconds, 90% less than 20 milliseconds, and the remaining transactions take no longer than round-trip Paxos latency across the diameter of the geographically dispersed deployment. Adding synchronous replication to near-by regions adds some latency, but only a small factor. In contrast, Paxos/Raft-based systems such as Spanner and Calvin take orders of magnitude longer latency to complete transactions for this benchmark (which is a simplified version of Figure 12 from the SLOG paper).